AWS S3 Event Notifications have "probably once" delivery
- Thursday July 25 2019
- messaging server distributed-systems aws
AWS S3 Event Notifications are one those of things that make previously hard tasks seemingly simple. When a key is written to in an AWS S3, you can get a notification about that write. For example, consider the following system
- A user uploads an image to a webserver as part of a new piece of content
- The webserver saves the image to an AWS S3 bucket
- An AWS Lambda receives the notitication of the new image
- The Lambda processes the image, scaling it down and re-encoding it in a better image format like WebP
- The Lambda replaces the image in the content with the optimized version
This is the typical use case for S3 Event Notifications. AWS S3 has eventual consistency for listing entries in a bucket, but this doesn't really apply to keys. As long as you write to a new key each time, you get read-after-write consistency. What this means is by the time you get a notification, you should be able to ready the key from S3. Of course, it still could be unavailable for some other reason like S3 being temporarily degraded. But you can solve this problem by just retrying the processing of the notification until you can actually read it from S3.
If you want to learn more about how to setup AWS S3 Event notifications, there is a complete guide from Amazon here.
S3 Event Notifcations are just another typical messaging system. When delivering messages from one system to another there are three general categories of how message delivery works. Each one of the following is a different set of guarantees
- At least once - each message is guaranteed to be delivered at least once
- At most once - each message is guaranteed to be delivered no more than once
- Exactly once - each message is guaranteed to be delivered exactly once
Of these three types, the first one is generally the most sane to implement. You can just keep sending the message until you get a reply from the other end that everything is OK. Implementing "at most once" it turns out is pretty easy as well. You just send the message to the other system once and ignore the reply from the other system. It is possible it got delivered, but if it didn't you met the guarantee anyways.
As far as "exactly once" delivery the subject is highly contentious. For example here is a well reasoned article by Tyler Threat explaining that it is impossible. Yet here is an article by Neha Narkhede that is available in Apache Kafka. The MQTT protocol goes so far as to make exactly once part of its specification. I am not going to down that rabbit hole, other than to state that "exactly once" is really nice to have when building distributed systems. But you can get by with just "at least once" behavior by handling duplicates.
So what do AWS S3 Event Notifications specify? This is the relevant text from Amazon
Amazon S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer. On very rare occasions, events might be lost. If your application requires particular semantics (for example, ensuring that no events are missed, or that operations run only once), we recommend that you account for missed and duplicate events when designing your application. You can audit for missed events by using the LIST Objects API or Amazon S3 Inventory reports. The LIST Objects API and Amazon S3 inventory reports are subject to eventual consistency and might not reflect recently added or deleted objects.
Update - This text was changed to remove the "events might be lost" in February 2020. You can view the original on Github here. The change can be viewed here. Thanks to Zac Charles for pointing this out.
So there is a section in there about "operations run only once" and duplicates. This hints at an "at least once" type behavior. But in the same text it states "On very rare occasions, events might be lost". So clearly this means that some notifications will never be delivered.
What kind of architecture is this? I couldn't find anything to describe it, so I decided it is a "probably once" architecture. In other words, you get the following
- Messages that are delivered once
- Messages that are delivered multiple times
- Messages that are not delivered
This is in fact equivalent to "no guarantees at all" but the phrase "probably once" has a certain appeal to it. In my case I have an application that writes files to S3 at a regular interval. These files are processed by a lambda so they can be loaded into a database. This database is ultimately used in a customer facing application, so any duplicates gets noticed very quickly. Somehow I needed to come up with a way to deal with this pecuilar behavior of S3 Event Notifications.
Duplicates by the numbers
Before I set out to solve this, I wanted to try and understand how often this behavior was a problem. The lambda logs what it is processing each time it is invoked. So I was able to get all those log entries from CloudWatch and see what notifications had been delivered over a 104 hour period. In that time frame I got:
- 507706 S3 notifications
- 507549 unique S3 keys
- 154 S3 Keys with duplicate notifications
So 154 keys getting duplicate notifications is only a rate of 0.03%. But as I pointed out earlier, for my application this means that some users data would be totally wrong when duplicate delivery occurs. This duplication happens daily so it isn't something that can be handled retroactively.
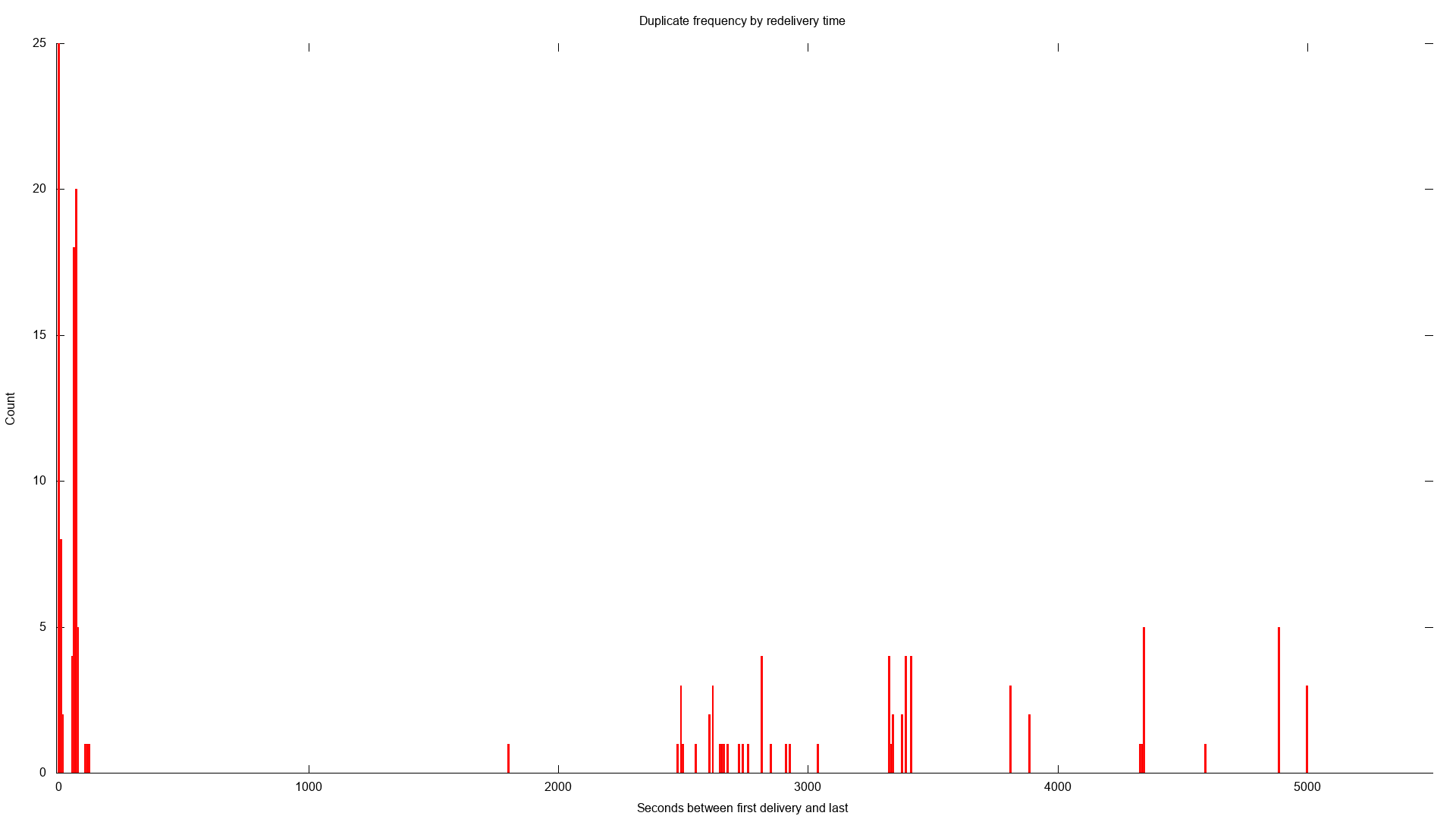
This plot shows the frequency of duplicates by the time between the original message and the duplicate. There is no clear pattern here
For most of the duplicate deliveries, the notification got delivered twice. For some it was actually delivered 3 times. The only thing I found consistent about the duplicates was they all have the same x-amz-id-2 set, so it is acceptable to use that to check for duplicates. The other observation I made was that the duplicates come pretty quickly, often within 15 seconds of one another. The latest duplicate to arrive was 22162 seconds after the original message or about 6 hours. So while you need to check for duplicates, you probably don't need to worry about duplicates showing up days later. However, I did see duplicates messages delivered only 62 milliseconds apart. In my case, the lambda takes a few seconds to run. This means that the lambda was actually running for the same key twice, simultaneously.
"Lost" events
The other problem with S3 Event notifications is "lost" events. Detecting and quantifying "lost" events is a harder problem. At least is my case, the missing data just means a user sees nothing instead of wrong data. The recommendation from Amazon is that you perform a list operation in order to identify the lost notifications. Basically, you need to run an audit process. Your code would go through every key returned by the list operation checking to see if it has been processed yet. Of course, this implies that you have something to compare the results of the list against. This means that when you process an S3 Event notification, you need to keep a record of all the keys you have processed.
This itself becomes a problem. Just consider the following example
- Your code gets the S3 Event notification
- Your code processes the notification and take the appropriate action
- Your code goes to update the list of "processed keys"
- Updating the list of "processed keys" fails
After step 4, you'd have an issue where your "audit" would later decide the key hasn't been processed. The logical next step would be to process the key. This itself would create a duplicate processing of that key!
The other thing to consider is that S3 Event notifications aren't instant. After a key is written to, the notification takes a little while to arrive. So if you run an audit process, you need to ignore recently written keys. Otherwise your code is going to decide that the newest keys have been lost, when in fact they just haven't been delivered yet. I decided the cutoff for what is "recent" is anything in the past 12 hours. This isn't really based off anything from Amazon as I couldn't find any recommendation for this.
Dealing with all of this
So having learned all of this, we need to come up with some way to deal with. The easiest way to deal with this is to try and build your system such that multiple processing of the same key from S3 has no negative effects. If you can't do that, your notification processor needs to be structured like this
- When each notification is received, check to see if it has been processed already
- If it has already been processed, discard it
- Obtain an exclusive lock on processing that key
- Process the key
- Mark the key as having been processed and release the lock
This strategy ignores duplicates because a list of processed keys is always checked first. By using an exclusive lock for each key, the problem of two duplicates arriving nearly simultaneously is also mitigated. The most practical way to implement this list and exclusive locking pattern is a single table in a relational database. One column is the S3 Key. Another column is a "state" enumeration with the following possible values
PROCESSING- the key is being processedPROCESSED- the key has been processedFAILED- they key was attempted to be processed but failed
If the processor gets a notification and a row already exists with anything other than a FAILED state, it just ignores it as a duplicate. If the row for the key doesn't exist yet, it adds the row and puts the state as PROCESSING. Whenever processing is complete, the state is updated to PROCESSED.
If for some reason the processor can't connect to the database at the start of things, it just aborts. But if it can't update the row after processing, then the row gets left in the PROCESSING state. This is less than ideal but acceptable. The real shortcoming is if the processor can't process the S3 key and it can't set the state to FAILED. This means that the key never gets processed. But, this does in fact implement an "as most once" system of message delivery. I recommend that you have some sort of notification or warning that notifies someone on an engineering team if a large number of rows are winding up in the PROCESSING state for too long. It probably means your processor is taking too long or is just broken.
On a daily basis you need to run an audit process that lists all the keys in the S3 Bucket. Any recently written keys are ignored. The audit process searches for keys that either don't have a row, or the row is left in the FAILED state. At this time, those keys are submitted for processing again.
You'll also need to eventually purge old entries from the table, otherwise it grows unbounded in size over time. The audit process needs to avoid resubmitting these keys. The simplest way to do this is to just keep the past 30 days of rows and have the audit process ignore any keys in S3 older than that time period. Due to this, you probably want to add a "last updated" column or similar to your table that is a timestamp representing the last time the row had some activity.