Calling WSJT-X encoding and decoding functions from C
WSJT-X is "weak signal software" used primarily by amateur radio operators. I use this software with my computer connected to an amateur radio transceiver. The computer sound card interfaces with what would normally be the speaker and microphone of a two-way radio. I can contact other amateur radio operators all over the world this way. One common modulation scheme for this is known as FT8 which transmit a short text message in approximately 15 seconds. This is actually lots of fun, but I won't talk at length about that.

My laptop connected to my amateur radio as a modem
Ever since I first used WSJT-X, I wanted to know more about how the software worked. After all, it does basically just process an audio stream to produce data outputs. Over time, I've learned more about the various techniques used for digital signal processing but my strengths don't really lie there. Instead what I'd like to do is just come up with a way to call the existing code in WSJT-X. There are a couple diffent motivations for this, but the first step is actually getting this done.
The original WSJT-X codebase
The way most people interact with WSJT-X and its various digital modes is through a graphical user interface. The graphical user interface in this case is written in the Qt framework using C++. As it turns out, all the C++ code does it put an interface around some existing code written by the original authors. So understanding the C++ code is not needed at all.
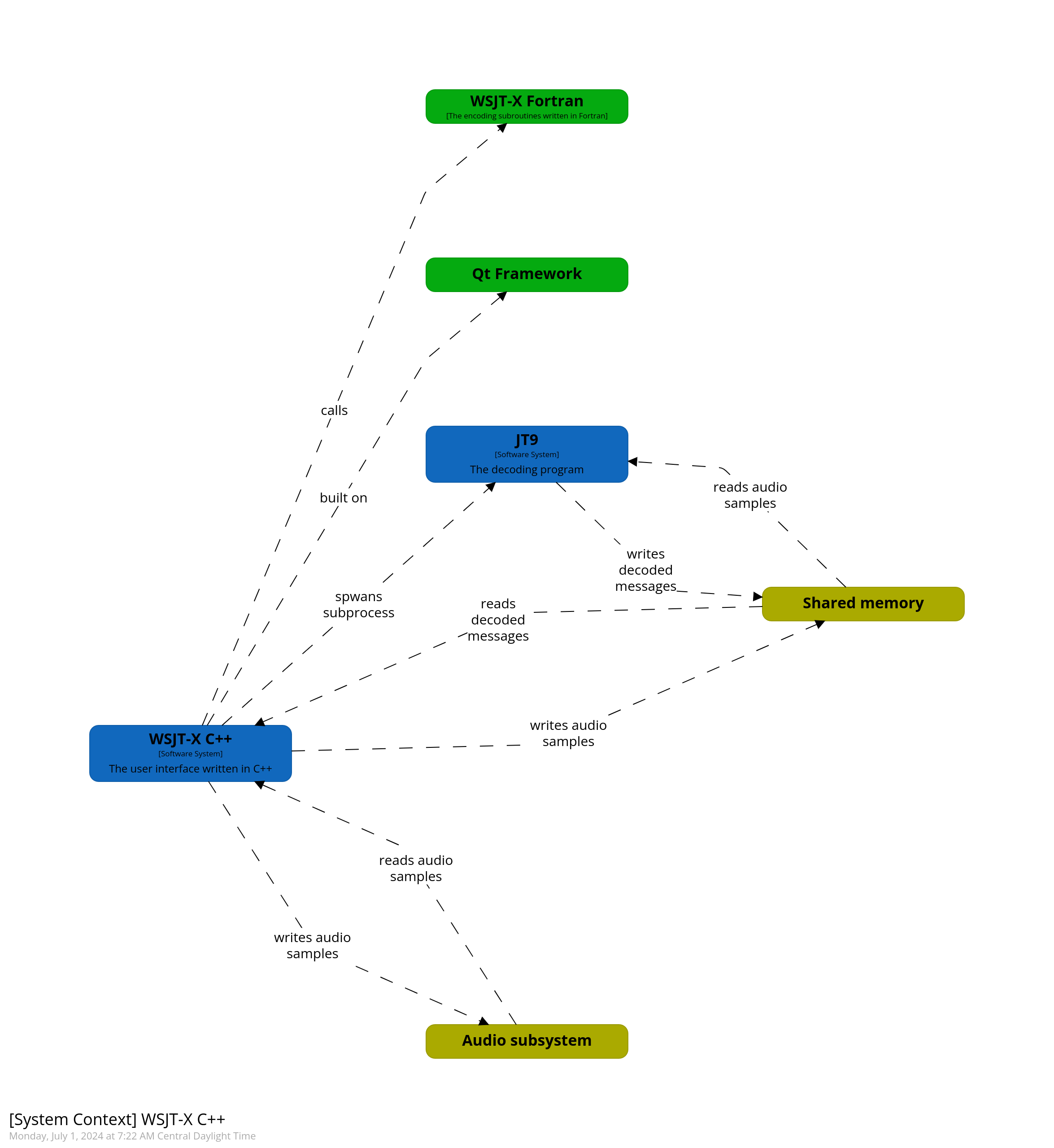
The internal architecture of WSJT-X
The underlying signal processing library is written in Fortran 90. Fortran 90 remains popular in academic and scientific groups for many programming tasks, with projects like WRF being written primarily in Fortran. Calling Fortran 90 code from C code is relatively interesting because it requires no special foreign function interface like you were trying to call Java code from C. A Fortran subroutine named computeThing becomes a symbol named computeThing_ when compiled. So if you want to call that function from C, you can just declare a function like this in a header file.
void computeThing_(void);
Your program can just call computeThing_() anywhere to call Fortran code. If you pass arguments to a Fortran function, its a bit unusual. If you have a Fortran function named computeDoubleThing that takes an integer argument it would be declared like this in your C header
void computeDoubleThing_(int* x);
Fortran passes arguments by reference, which means it is passed by a pointer from the perspective of a C program. It is possible declare subroutines that don't do this but every Fortran codebase I've interacted with just sticks with the default. There is a bunch more nuance to how this works and this is not meant to be a complete reference. So it is possible to call the encoding and decoding functions from C, it just involves unusual function declarations.
Given that I already knew this was possible, I just looked around in the C++ code until I found the declarations that looked like Fortran functions
// this code originally from 'mainwindow.cpp' in WSJT-X #define FCL fortran_charlen_t extern "C" { //----------------------------------------------------- C and Fortran routines void symspec_(struct dec_data *, int* k, double* trperiod, int* nsps, int* ingain, bool* bLowSidelobes, int* minw, float* px, float s[], float* df3, int* nhsym, int* npts8, float *m_pxmax, int* npct); void hspec_(short int d2[], int* k, int* nutc0, int* ntrperiod, int* nrxfreq, int* ntol, bool* bmsk144, bool* btrain, double const pcoeffs[], int* ingain, char const * mycall, char const * hiscall, bool* bshmsg, bool* bswl, char const * ddir, float green[], float s[], int* jh, float *pxmax, float *rmsNoGain, char line[], fortran_charlen_t, fortran_charlen_t, fortran_charlen_t, fortran_charlen_t); void genft8_(char* msg, int* i3, int* n3, char* msgsent, char ft8msgbits[], int itone[], fortran_charlen_t, fortran_charlen_t);
The underscore at the end is the giveaway. Since the UI is written in C++, it declares these functions as extern "C" so the calling convention winds up matching the Fortran subroutines. I dug around in the underlying Fortran codebase and found declarations for subroutines matching the names I saw there
subroutine genft8(msg,i3,n3,msgsent,msgbits,itone) ! Encode an FT8 message, producing array itone(). use packjt77 include 'ft8_params.f90' character msg*37,msgsent*37 character*77 c77 integer*1 msgbits(77),codeword(174) integer itone(79) integer icos7(0:6) integer graymap(0:7)
Fortran is weird (notice a pattern here) in that arguments are declared as part of a subroutine, but the type of the arguments is specified by the declaration of what looks like a local variable inside the function. So by reading through the top of the subroutine, I could figure out what parameters I needed to declare on the C function headers.
Encoding an FT8 message
I eventually came to the conclusion I only needed 2 functions to get encoding of a message working which are genft8 and genft8_wave. These functions are used together to take a text message like "HELLO RADIO" and produce an audio waveform. I was able to borrow the declaration from the C++ code directly, although I did confirm it made sense manually based off the Fortran subroutines
void genft8_(char* msg, int* i3, int* n3, char* msgsent, char ft8msgbits[], int itone[], fortran_charlen_t, fortran_charlen_t); void gen_ft8wave_(int itone[], int* nsym, int* nsps, float* bt, float* fsample, float* f0, float xjunk[], float wave[], int* icmplx, int* nwave);
As it would turn out, having this knowledge in hand was only about 10% of the work required. I do of course need to know what values to call these functions with. The C++ code only calls these functions in one place
// this code originally from 'mainwindow.cpp' in WSJT-X if(m_mode=="FT8") { if(SpecOp::FOX==m_specOp and ui->tabWidget->currentIndex()==1) { foxTxSequencer(); } else { int i3=0; int n3=0; char ft8msgbits[77]; genft8_(message, &i3, &n3, msgsent, const_cast<char *> (ft8msgbits), const_cast<int *> (itone), (FCL)37, (FCL)37); int nsym=79; int nsps=4*1920; float fsample=48000.0; float bt=2.0; float f0=ui->TxFreqSpinBox->value() - m_XIT; int icmplx=0; int nwave=nsym*nsps; gen_ft8wave_(const_cast<int *>(itone),&nsym,&nsps,&bt,&fsample,&f0,foxcom_.wave, foxcom_.wave,&icmplx,&nwave); if(SpecOp::FOX == m_specOp) { //Fox must generate the full Tx waveform, not just an itone[] array. QString fm = QString::fromStdString(message).trimmed(); foxGenWaveform(0,fm); foxcom_.nslots=1; foxcom_.nfreq=ui->TxFreqSpinBox->value(); if(m_config.split_mode()) foxcom_.nfreq = foxcom_.nfreq - m_XIT; //Fox Tx freq QString foxCall=m_config.my_callsign() + " "; ::memcpy(foxcom_.mycall, foxCall.toLatin1(), sizeof foxcom_.mycall); //Copy Fox callsign into foxcom_ foxgen_(); } } }
From this code, we can see that first genft8 is called and immediately that is followed by a call to gen_ft8wave. You can ignore all the checks about a "fox" as I know that option is disabled by default in WSJT-X.
Arguments of genft8
So I was able to break down the arugments of genft8 as follows
message- the message you want to send in ASCII formati3- always the value 0. This appears to be the only valid valuen3- always the value 0. This appears to be the only valid valuemsgsent- this contains the message that is being sent, after the function returnsft8msgbits- this contains the bits that are being sent, after the function returns.itone- this is an integer array declared asitone[MAX_NUM_SYMBOLS];withMAX_NUM_SYMBOLSbeing250- the length of
message, not including the trailing terminator - the length of
msgsent, not including the trailing terminator
Options 7 & 8 can practically always be 37 as shown. The length of the message that can be encoded is very short. If you want to check that what was requested matches the encoded message you can compare msgsent to your original message afterwards. Other than that, you can ignore it.
Once genft8_ is complete the actual data you need is stored into itone and needs to be passed to genft8_wave
Arguments of genft8_wave
itone- this the array storing a list of tones, set by the call togenft8nsym- the number of symbols to encode, this is always 79 for FT8nsps- the number of symbols per secondbt- this is always2.0. This appears to be the only valid valuefsample- the sample rate of the audio to generatef0- the frequency to generate the signal at in Hzxjunk- this has to be a pointer to a valid arraywave- this has to be a pointer to a valid array, the output samples are generated hereicmplx- 0 or 1. Zero generates real valued samples whereas 1 generates complex samples. Always zero for this purposenwave- the number of samples to generate
This subroutine is relatively interesting. The input is always from itone. The output should always be generated into wave. The usage of this in practice is always foxcom_.wave. The underscore at the end of the name indicates this is some sort of shared global value declared in Fortran code. After digging around a bunch I realized that this is just declared as an array of Fortran REAL values. This corresponds to a type of float in C. I have no idea why the WSJT-X authors decided to use foxcom_.wave which is obviously not thread safe. In the larger picture of things I don't think it matters much.
When gent8_wave returns it has written into the array wave the number of samples specified by nwave. These are floating point value on the range of \([-1.0, 1.0]\) so full scale audio. In order to use this value it needs to either be fed to a sound card or written to a file. I chose to write it into a wave sound file. I've actually written about doing this before so I am not going to repeat that again.
Decoding an FT8 message
Unfortunately for myself, decoding is nowhere near as simple. One of the things I had figured out about WSJT-X was the C++ code never actually calls the decoding subroutines directly. Instead it uses a subprocess it launches and passes data via shared memory to it. To figure this out, I looked at a command named jt9 that is included with WSJT-X. It is a command line program that can decode most of the supported digital modes. A Fortran program's entry point is declared by the program keyword. In this case, the program is defined in the file wsjtx/lib/jt9.f90. After sorting through all the option parsing code I realized all this really does is call a Fortran subroutine called multimode_decoder. This subroutine is actually huge and is declared in wsjtx/lib/decoder.f90.
I was able to pull out the parts relevant to the FT8 decoding process
type, extends(ft8_decoder) :: counting_ft8_decoder integer :: decoded end type counting_ft8_decode type(counting_ft8_decoder) :: my_ft8 call my_ft8%decode(ft8_decoded,id2,params%nQSOProgress,params%nfqso, & params%nftx,newdat,params%nutc,params%nfa,params%nfb, & params%nzhsym,params%ndepth,params%emedelay,ncontest, & logical(params%nagain),logical(params%lft8apon), & logical(params%lapcqonly),params%napwid,mycall,hiscall, & params%ndiskdat)
So there are 3 things going on
- the declaration of a user defined type that extends the
ft8_decodercalledcounting_ft8_decoder - an initialization of a single instance of
counting_ft8_decoder - an invocation of the
decodesubroutine that is part of the parentft8_decodertype
This is basically a worst case scenario. Although Fortran is commonly known as a practical language for numerical data processing, it does include user defined data types. While calling Fortran subroutines is possible from C, calling user defined types is much more complex. To make things worse, the decode subroutine returns absolutely no data! All data is returned through callback invocation. The first argument to decode is actually a function pointer that is called each time a message is decoded.
After thinking about ways to work around this for a while, I eventually settled on the idea of using shims written in Fortran to solve this. What I came up with was writing a function in Fortran that would take all the arguments I needed, construct a single ft8_decoder and then call decode. I decared a function like this
subroutine decode_ft8_shim(callback, id2, nQSOProgress, nfqso, nftx, & newdat, nutc, nfa, nfb, nzhsym, ndepth, emedelay, & ncontest, nagain, lft8apon, lapcqonly, napwid, mycall, & hiscall, ndiskdat) use ft8_decode use iso_c_binding, only: c_int, c_short, c_float, c_char, c_bool, c_ptr, c_funptr, C_F_PROCPOINTER implicit none
The statement use iso_c_binding indicates that this Fortan code should use variables that are strictly compatible with C code. The actual WSJT-X Fortran code does this as well, but only sporadically. Using this shim allowed me to access the decoding directly from C. This worked, but left me in a bit of a bind. I had to declare my callback function like this in C
static void mycallback( void* self, float* sync, int* snr, float* dr, float* freq, char* decoded, int* nap, float* qual, FCL decoded_len)
This is a C-Language function that is passed by function pointer to the Fortran code and invoked as a callback. This is why the arguments are all pointers. There is nowhere in any of this to actually store results. The first argument void* self actually points to the ft8_decoder which I am trying to avoid editing. The rest of the arguments are just the data. I came up with an unlikely solution to this which was thread local storage. I have never had a compelling reason to use this in C, but it seems appropriate. I declared additional types and variables like this
typedef struct{ float sync; int snr; float dr; float freq; char decoded[MSG_LENGTH]; int nap; float qual; }decodeResult; typedef struct{ size_t cnt; size_t len; decodeResult* results; }decodeArray; static __thread decodeArray* decodes;
The __thread indicator tells the GCC toolchain that this variable is thread local. The callback function is implemented to apend results into decodes->results each time it is invoked. For this to work all that has to be done is
- assign
decodesto point at a validdecodeArray - pass
mycallbackto the FT8 decoding fortran shim - set
decodestoNULLafter it returns - process the data in the
decodeArraystructure
This is a simple solution to getting the data back to the caller in a structured manner. I don't think this was the intended usage of thread local variables but it fits. The only way the thread could change would be some abuse of setjmp() / longjmp() functions which I don't see happening in this code.
The second argument to the decode function is declared in Fortran as something integer*2 id2(120*12000). The type integer*2 has no official C binding, but it works out to be a 2 byte signed integer. So the C equivalent declaration is int16_t id2[120*12000]. This argument should contain the audio samples to be processed. Unlike the encoding code, this does not use the float type. The sample rate must always be 12000 samples per second. So I decided to implement a program that would only accept wave files already with a sample rate of 12000 samples per second.
Getting everything to compile and link
Now that I had the ability to interface with the original Fortran code, I needed to compile it so I could interact with it. I copied over most of the library code to my project from WSJT-X 2.6.1. The original project uses CMake to compile, which I did not want to spend the overhead of setting that up presently. What I did do was look at the invocation of gfortran while WSJT-X compiled. I noticed it used the following Fortran flags
-Wall -Wno-conversion -fno-second-underscore -fbounds-check -funroll-all-loops -fno-f2c -ffpe-summary=invalid,zero,overflow,underflow
So I was able to copy those over and get things compiling just fine. I already knew there was a dependency on FFTW3 (a library for computing Fourier transforms) but I couldn't get the code to link. I eventually realized that WSJT-X depends on the single precision version of FFTW3 which has to be linked with -lfftw3f. You also need to specify -lgfortran & -lm since there are run time dependencies associated with the Fortran toolchain.
I figured this would be all. But it turns out there were several missing symbols. I eventually located the implementation in files like lib/qra/q65/q65.c. So as it would turn out some of WSJT-X is actually written in C. This is no problem to compile and link. What was more intriguing was the last set of symbols that could not be found were related to CRC codes. I eventually found implementations in files such as lib/crc10.cpp. Looking at the implementation I see this
#include <boost/crc.hpp> #include <boost/config.hpp> extern "C" { short crc10 (unsigned char const * data, int length); bool crc10_check (unsigned char const * data, int length); } #define POLY 0x08f #ifdef BOOST_NO_CXX11_CONSTEXPR #define TRUNCATED_POLYNOMIAL POLY #else namespace { unsigned long constexpr TRUNCATED_POLYNOMIAL = POLY; } #endif // assumes CRC is last 16 bits of the data and is set to zero // caller should assign the returned CRC into the message in big endian byte order short crc10 (unsigned char const * data, int length) { return boost::augmented_crc<10, TRUNCATED_POLYNOMIAL> (data, length); } bool crc10_check (unsigned char const * data, int length) { return !boost::augmented_crc<10, TRUNCATED_POLYNOMIAL> (data, length); }
So this is actually C++ code declared with the extern "C" specifier so it is C compatible which is then invoked from Fortran. It is using the Boost library but it must be header only because I did not link with any Boost libraries to produce a working program. This did require me to add -lstdc++ which satisfied the last dependency so a working program could be compiled.
Testing it out
At this point I had programs for both encoding and decoding FT8 from wave files. The normal way to use this would be to connect to a radio to send and receive messages. But since the computer in this setup just acts like a modem, you can actually use this between two computers. If you want to be particularly lazy you can just turn the microphone gain up on your laptop until the audio from the speakers is audible.
So I encoded a message by running this
$ ./express8 encode ft8 --verbose demo0.wav hydrogen18 message to encode: hydrogen18 opening file demo0.wav for output as wave file with 1 channels, 606720 samples at 48000 sample per second file demo0.wav written successfully
This produces a wave file demo0.wav with just the message "hydrogen18". You can play this with any normal audio program like VLC. You can also visualize the output like this with ffmpeg.
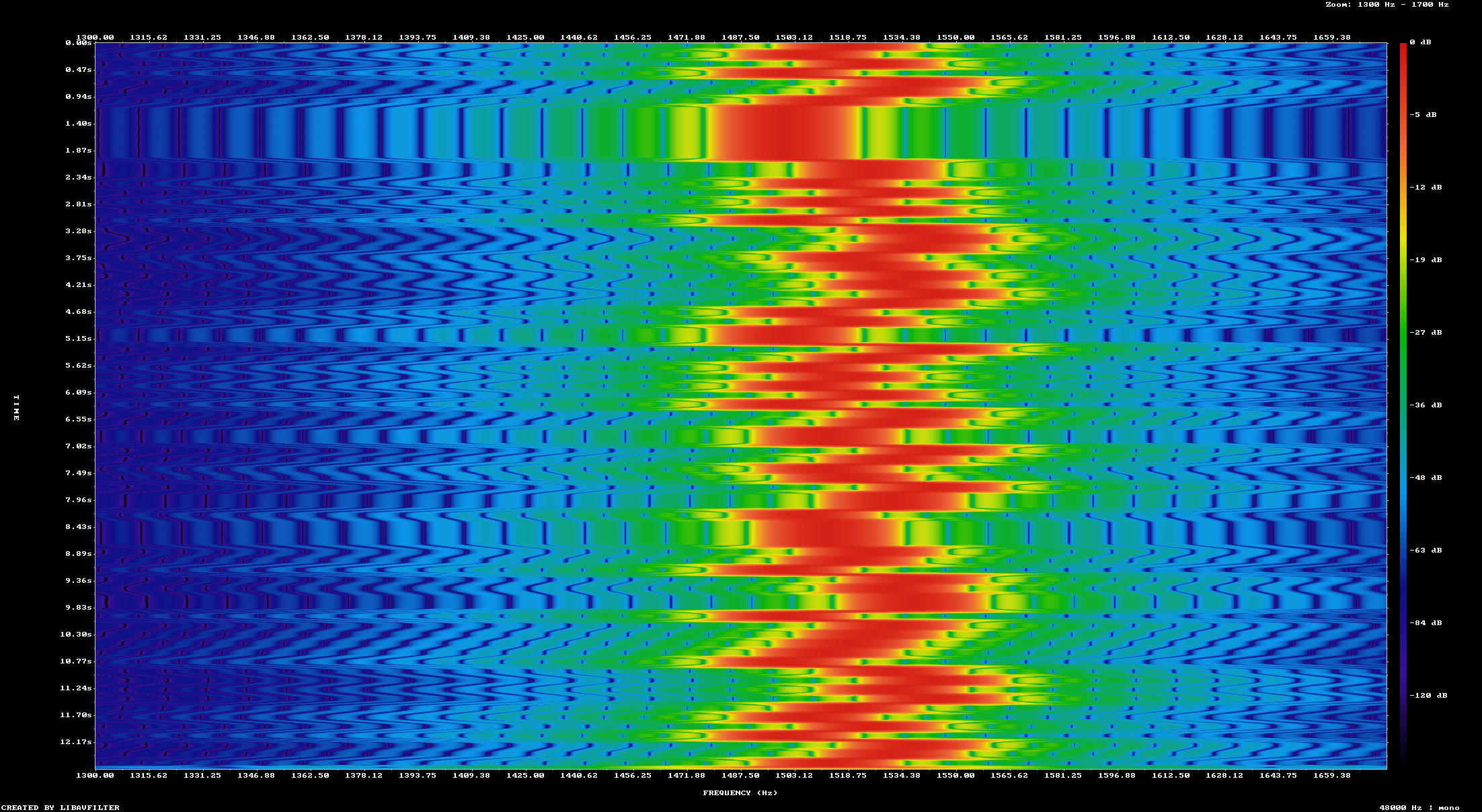
This show the power density with different colors. The transmitted tones are in red which is the highest power level.
To complete testing my program I need to record this as audio. I am running Ubuntu so I used arecord to record from pulseaudio for 15 seconds at 12000 samples per second.
arecord -D pulse -r 12000 -f S16_LE -t wav recording_of_demo0.wav -d 15
Make sure to use pavucontrol to mute the monitor of your systems internal audio like this
Now all that is needed is to decode the message, which comes out in CSV format
$ ./express8 decode ft8 tmp/recording_of_demo0.wav index, message, sync, SNR, dr, freq, nap, qual 0, HYDROGEN18, 122.9, 26, -0.4, 1500.0, 0, 1.00
The original text message "hydrogen18" is decoded as "HYDROGEN18" because FT8 does not encode the case of latin characters. The column "SNR" in the output has a value of 26 which is exceptionally high because the room I recorded this sample message in has very little background noise.
Finding a bug in WSJT-X
Whenever I write C, C++ or other languages requiring manual memory management I use valgrind to catch errors where I do not properly free() a section of memory that is allocated with malloc(). This tool is very helpful. It can also catch other errors, like using a pointer that has never been initalized. When I run my decoder with valgrind with one message in the audio I get a clean output as shown here.
$ valgrind --leak-check=full ./express8 decode ft8 ../tmp/recording_of_demo0.wav ==68549== Memcheck, a memory error detector ==68549== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==68549== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info ==68549== Command: ./express8 decode ft8 ../tmp/recording_of_demo0.wav ==68549== ==68549== Warning: set address range perms: large range [0x18d000, 0x16031000) (defined) index, message, sync, SNR, dr, freq, nap, qual 0, HYDROGEN18, 122.9, 26, -0.4, 1500.0, 0, 1.00 ==68549== ==68549== HEAP SUMMARY: ==68549== in use at exit: 1,876,608 bytes in 1,630 blocks ==68549== total heap usage: 73,875 allocs, 72,245 frees, 60,279,127 bytes allocated ==68549== ==68549== LEAK SUMMARY: ==68549== definitely lost: 0 bytes in 0 blocks ==68549== indirectly lost: 0 bytes in 0 blocks ==68549== possibly lost: 0 bytes in 0 blocks ==68549== still reachable: 1,876,608 bytes in 1,630 blocks ==68549== suppressed: 0 bytes in 0 blocks ==68549== Reachable blocks (those to which a pointer was found) are not shown. ==68549== To see them, rerun with: --leak-check=full --show-leak-kinds=all ==68549== ==68549== For lists of detected and suppressed errors, rerun with: -s ==68549== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
This is good because it means on a normal run of the program I have no memory leak issues. The WSJT-X project comes with several audio files that are samples of FT8 transmissions. So I decided to decode those as well to test my program. I ran it with valgrind in this case as well
ericu@ericu-acer-laptop:~/express8$ valgrind ./express8 decode ft8 ft8_sample_2.wav ==68555== Memcheck, a memory error detector ==68555== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==68555== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info ==68555== Command: ./express8 decode ft8 ft8_sample_2.wav ==68555== ==68555== Warning: set address range perms: large range [0x18d000, 0x16031000) (defined) ==68555== Conditional jump or move depends on uninitialised value(s) ==68555== at 0x168F42C7: lroundf (s_lroundf.c:42) ==68555== by 0x127FD7: __ft8_decode_MOD_decode (ft8_decode.f90:211) ==68555== by 0x125D44: decode_ft8_shim_ (ft8_shim.f90:46) ==68555== by 0x15BC95: decode_ft8 (decode_ft8.c:457) ==68555== by 0x10B6EA: decode_all (main.c:63) ==68555== by 0x10B76E: main (main.c:91) ==68555== ==68555== Conditional jump or move depends on uninitialised value(s) ==68555== at 0x168F42CC: lroundf (s_lroundf.c:44) ==68555== by 0x127FD7: __ft8_decode_MOD_decode (ft8_decode.f90:211) ==68555== by 0x125D44: decode_ft8_shim_ (ft8_shim.f90:46) ==68555== by 0x15BC95: decode_ft8 (decode_ft8.c:457) ==68555== by 0x10B6EA: decode_all (main.c:63) ==68555== by 0x10B76E: main (main.c:91) ==68555== index, message, sync, SNR, dr, freq, nap, qual 0, W1FC F5BZB -08, 249.3, 15, 0.3, 2571.4, 0, 1.00 1, CQ F5RXL IN94, 37.1, -2, -0.8, 1196.9, 0, 0.98 2, WM3PEN EA6VQ -09, 33.3, 13, -0.1, 2157.2, 0, 1.00 3, K1JT HA0DU KN07, 16.6, -13, 0.3, 589.6, 0, 0.77 4, A92EE F5PSR -14, 13.6, -7, 0.1, 723.4, 0, 0.92 5, K1BZM EA3GP -09, 13.4, -3, -0.1, 2695.4, 0, 0.16 6, N1JFU EA6EE R-07, 11.2, -13, 0.3, 640.6, 0, 0.81 7, N1PJT HB9CQK -10, 10.7, -3, 0.2, 465.6, 0, 0.15 8, K1JT EA3AGB -15, 7.9, -16, 0.1, 1648.5, 0, 0.70 9, W1DIG SV9CVY -14, 7.1, -7, 0.4, 2733.9, 0, 0.57 10, W0RSJ EA3BMU RR73, 5.9, -16, 0.3, 399.5, 0, 0.65 11, XE2X HA2NP RR73, 1.9, -11, 0.2, 2852.5, 0, 0.69 12, KD2UGC F6GCP R-23, 9.7, -6, 0.4, 472.4, 0, 0.82 13, K1BZM EA3CJ JN01, 9.1, -7, 0.2, 2522.4, 0, 0.46 ==68555== ==68555== HEAP SUMMARY: ==68555== in use at exit: 1,876,608 bytes in 1,630 blocks ==68555== total heap usage: 78,342 allocs, 76,712 frees, 136,729,622 bytes allocated ==68555== ==68555== LEAK SUMMARY: ==68555== definitely lost: 0 bytes in 0 blocks ==68555== indirectly lost: 0 bytes in 0 blocks ==68555== possibly lost: 0 bytes in 0 blocks ==68555== still reachable: 1,876,608 bytes in 1,630 blocks ==68555== suppressed: 0 bytes in 0 blocks ==68555== Rerun with --leak-check=full to see details of leaked memory ==68555== ==68555== Use --track-origins=yes to see where uninitialised values come from ==68555== For lists of detected and suppressed errors, rerun with: -s ==68555== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
The messages are decoded successfully. There are no memory leaks but we do get a warning about Conditional jump or move depends on uninitialised value. I thought somehow I had caused this issue. The actual problem occurs rather deep in Fortran code. To try and determine if I was causing this issue I ran the original jt9 program included with WSJT-X to decode the same audio file. The actual output of valgrind was huge and included this
==68572== More than 10000000 total errors detected. I'm not reporting any more. ==68572== Final error counts will be inaccurate. Go fix your program!
So I think it is safe to say it is plausible that there are potential errors in WSJT-X. Focusing back on the original problem, the code from ft8_decode.f90 is in the middle of a huge function. But this gives the context
call ft8b(dd,newdat,nQSOProgress,nfqso,nftx,ndeep,nzhsym,lft8apon, & lapcqonly,napwid,lsubtract,nagain,ncontest,iaptype,mycall12, & hiscall12,f1,xdt,xbase,apsym2,aph10,nharderrors,dmin, & nbadcrc,iappass,msg37,xsnr,itone) call timer('ft8b ',1) nsnr=nint(xsnr)
The Fortran subroutine ft8b is one of the various subroutines that make up a part of the FT8 decoding process. The variable xsnr in this case is a variable with no declaration. In Fortran this is completely valid and it means that xnsr has type REAL. This is known as implicit typing in Fortran. The invocation nint is just rounding to nearest whole number.
Based on the fact that valgrind produces no warnings when only 1 message is decoded and that the call to ft8b is in a loop I guessed that this was related to the fact that the variable might not always be assigned by ft8b. It is important to realize that in Fortran all parameters are by default pass by reference. The actual implementation of ft8b is 464 lines of Fortran code. The argument xsnr is only assigned at the very end of the loop
xsnr=0.001 xsnr2=0.001 arg=xsig/xnoi-1.0 if(arg.gt.0.1) xsnr=arg arg=xsig/xbase/3.0e6-1.0 if(arg.gt.0.1) xsnr2=arg xsnr=10.0*log10(xsnr)-27.0 xsnr2=10.0*log10(xsnr2)-27.0 if(.not.nagain) then xsnr=xsnr2
The loop that this lives in has tons of conditions that lead to it terminating early, so at this point I just presumed it was hitting one of those. In order to test this, I just assigned xsnr = 0.0 before calling ft8b. This eliminated the warning from valgrind and the actual decoded output is the same. So this uninitialized value is inconsequential to the correctness of the program but I fixed it anyways.
Adding more features
One thing I had always wanted to do was to have the ability to transmit multiple FT8 messages at once. A normal transmission of FT8 is a series of pure tones. The bandwidth of the signal is only about 50 Hz. But any normal amateur radio nowadays happilly transmits an audio signal of 0-2500 Hz or more with any number of simultaneous tones. So if we can generate a bunch of FT8 signals all in one audio file, they can be transmitted all together. There are of course still disadvantages to doing this, but I'm not really going to go into the details of signalling theory. With a bandwidth 2000 Hz we could conceivably pack in a theoretical maximum of 40 FT8 signals
Since I already had figured out how to encode one message I was most of the way to a solution for this. The simple wave file format supports basically any number of channels in a single audio track. So my approach was to take as input to the program a text file that had messages on each line. The existing Fortran functions are used to generate audio samples. Each one becomes a separate channel in the wave output file. So I was able to implement a program like this
./express8 encode multift8 --verbose -b 600 demo1.wav words.txt encoding message #1 at 600.0 Hz: alpha encoding message #2 at 655.0 Hz: beta encoding message #3 at 710.0 Hz: charlie encoding message #4 at 765.0 Hz: qux encoding message #5 at 820.0 Hz: foo encoding message #6 at 875.0 Hz: bar encoding message #7 at 930.0 Hz: meow opening file demo1.wav for output as wave file with 7 channels, 606720 samples at 48000 sample per second file demo1.wav written successfully
I used the -b 600 switch to set an initial frequency of 600 Hz. The speakers in my laptop are pretty awful and do not seem to create low frequency sounds much at all. We can inspect this the mediainfo command to confirm it has 7 output channels
$ mediainfo demo1.wav General Complete name : demo1.wav Format : Wave File size : 8.10 MiB Duration : 12 s 640 ms Overall bit rate mode : Constant Overall bit rate : 5 376 kb/s FileExtension_Invalid : act at9 wav Audio Format : PCM Format settings : Little / Signed Codec ID : 1 Duration : 12 s 640 ms Bit rate mode : Constant Bit rate : 5 376 kb/s Channel(s) : 7 channels Sampling rate : 48.0 kHz Bit depth : 16 bits Stream size : 8.10 MiB (100%)
So at this point I used the same trick of recording using arecord while playing the original file. Using ffmpeg again I can visualize the generated file and the recorded file
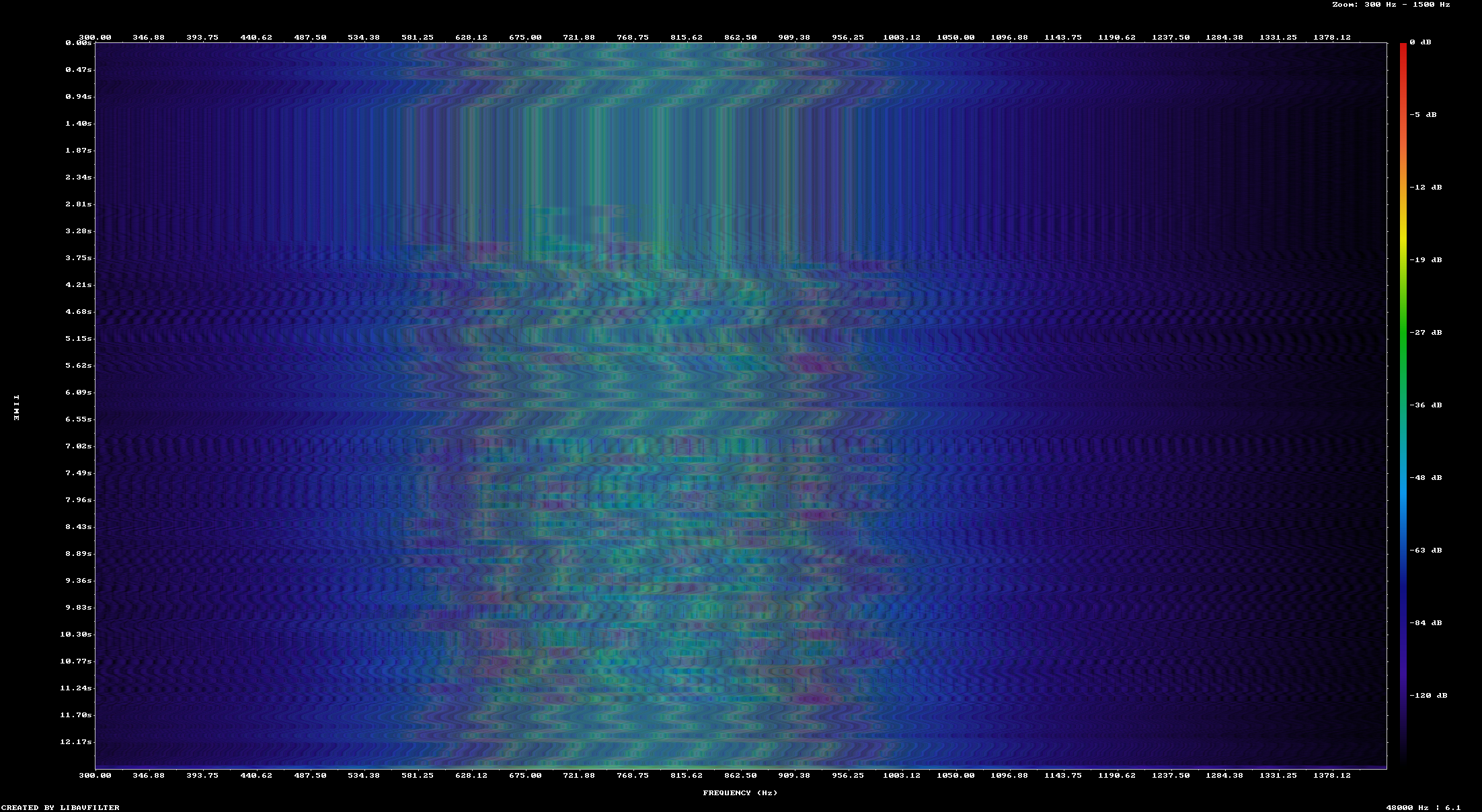
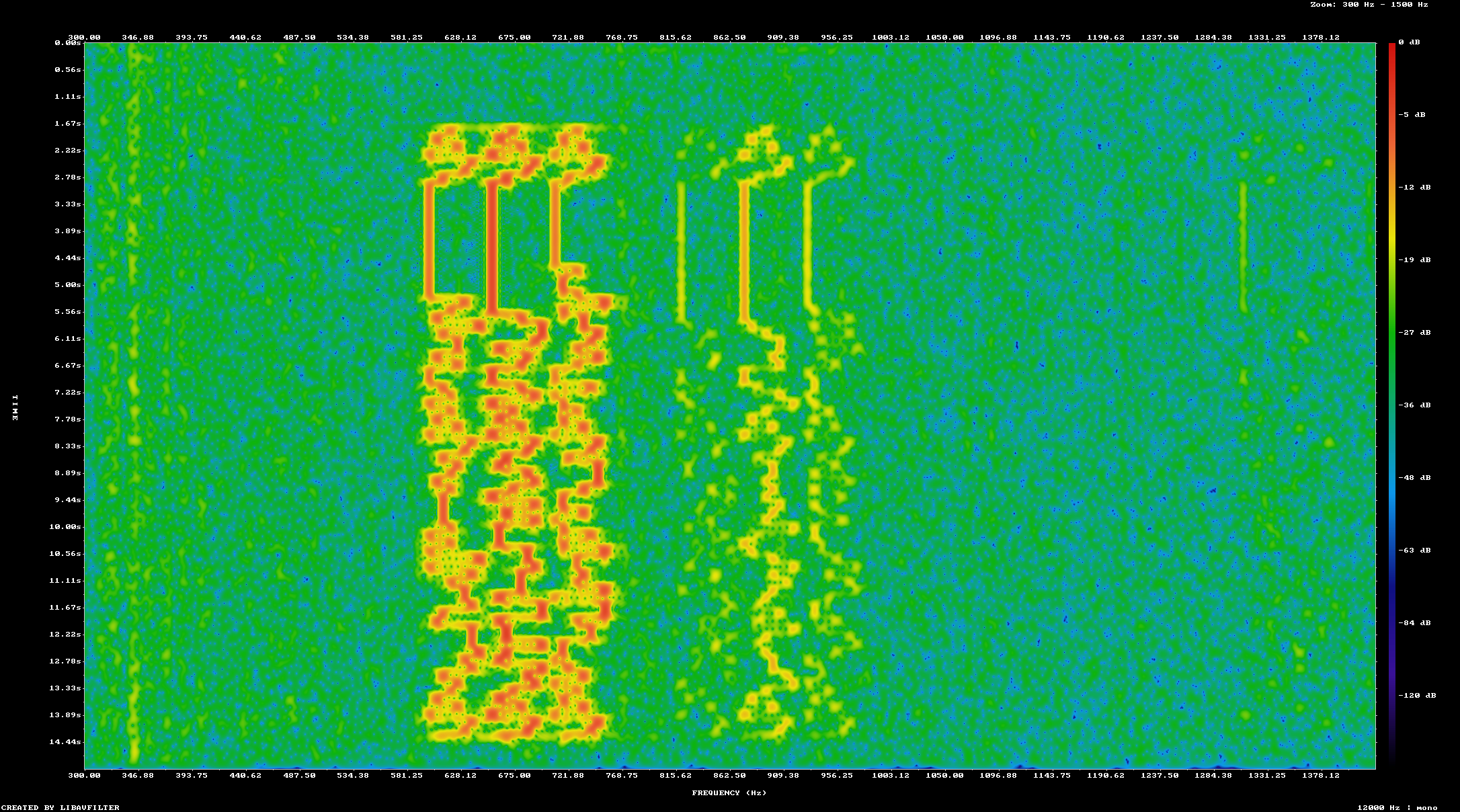
The 7 messages are all present in the generated file but message 5 doesn't show up in the output. This is confirmed by running the decoder on the recording
$ ./express8 decode ft8 ../tmp/recording_of_demo1.wav index, message, sync, SNR, dr, freq, nap, qual 0, ALPHA, 14.8, 10, 1.4, 600.0, 0, 1.00 1, BAR, 13.1, 0, 1.4, 875.0, 0, 1.00 2, BETA, 12.2, 14, 1.4, 655.2, 0, 1.00 3, MEOW, 6.6, -6, 1.4, 929.8, 0, 1.00 4, FOO, 3.7, -9, 1.4, 819.8, 0, 0.96 5, CHARLIE, 1.9, 9, 1.4, 708.8, 0, 0.85
My theory was this is just caused by me using a cheap laptop with an even cheaper microphone and speakers to test this out. But I actually recorded from the system monitor and it still didn't decode. After looking at the original audio tone, I determined that the generated audio is pretty messy. I don't know enough about the encoding to understand this at present. The reason why it doesn't matter for transmitted radio signals is that the signal is so weak by the time it arrives at the destination that small noise components aren't really mesurable. But when you're generating a bunch of signals and adding them together the noise can be additive. So what I did was changed the spacing of the transmitted signals to be much wider at 120 Hz apart.
./express8 encode multift8 --verbose -b 600 --spacing 120 demo2.wav words.txt encoding message #1 at 600.0 Hz: alpha encoding message #2 at 720.0 Hz: beta encoding message #3 at 840.0 Hz: charlie encoding message #4 at 960.0 Hz: qux encoding message #5 at 1080.0 Hz: foo encoding message #6 at 1200.0 Hz: bar encoding message #7 at 1320.0 Hz: meow opening file demo2.wav for output as wave file with 7 channels, 606720 samples at 48000 sample per second file demo2.wav written successfully
This made absolutely no difference in the decoded output. I added in the ability to generate a wave file that is multiple messages encoded all into one channel
$ ./express8 encode multift8 -c --verbose -b 600 demo3.wav words.txt encoding message #1 at 600.0 Hz: alpha encoding message #2 at 655.0 Hz: beta encoding message #3 at 710.0 Hz: charlie encoding message #4 at 765.0 Hz: qux encoding message #5 at 820.0 Hz: foo encoding message #6 at 875.0 Hz: bar encoding message #7 at 930.0 Hz: meow opening file demo3.wav for output as wave file with 1 channels, 606720 samples at 48000 sample per second file demo3.wav written successfully
This finally produced a good decode of all the encoded messages
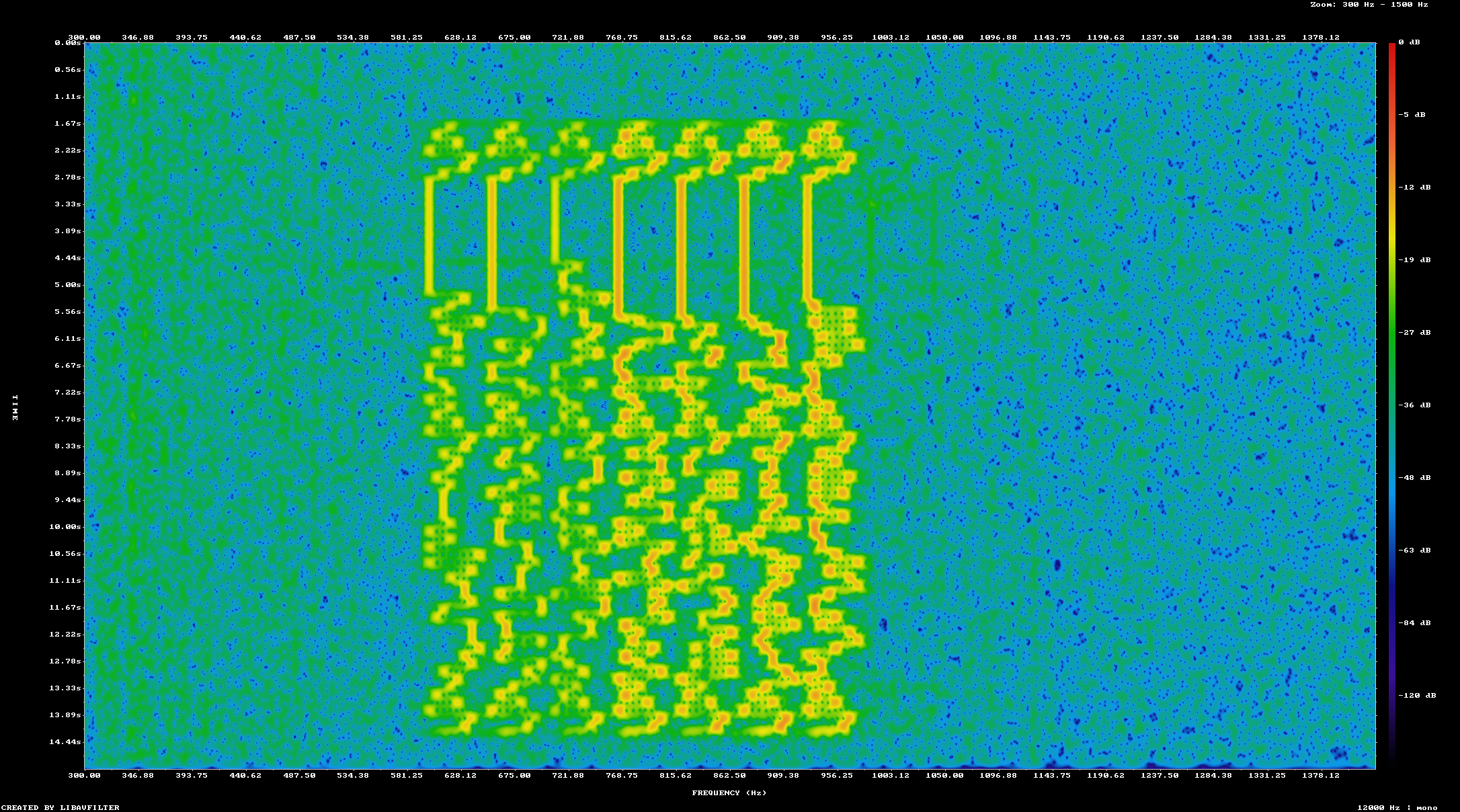
The recording spectrogram showing all transmitted messages clearly
$ ./express8 decode ft8 ../tmp/recording_of_demo3.wav index, message, sync, SNR, dr, freq, nap, qual 0, ALPHA, 28.4, 1, 1.3, 600.0, 0, 1.00 1, BAR, 22.5, 8, 1.3, 875.0, 0, 1.00 2, CHARLIE, 17.5, 1, 1.3, 709.9, 0, 1.00 3, QUX, 15.2, 7, 1.3, 765.1, 0, 1.00 4, FOO, 11.5, 6, 1.3, 820.2, 0, 1.00 5, BETA, 11.4, 2, 1.3, 655.2, 0, 1.00 6, MEOW, 8.8, 8, 1.3, 930.2, 0, 1.00
I am pretty sure what was happening here was VLC was somehow decided that my 7 channel wave file was 6.1 stereo audio and omitting one track because it believed that it is a subwoofer track.
Source code
All of the source code for this project is available on codeberg.