Restoring audio from the B-58 "Hustler" Voice Warning System
Someone uploaded the B-58 voice warning system audio to the Internet Archive a while back. I've always had an interest in military aviation, so this is quite interesting to me. The uploader has exactly one contribution with no information about who they are. There are 15 audio clips. One of which is actually a voice recording from Victor Mayer about an ejection event, which apparently he survived. That leaves 14 clips. The included page from the manual shows quite a few audio warnings

I located an actual PDF of the B-58 flight manual and it states states "The system provides twenty channels with nineteen pre-recorded messages arranged in priority of importance". The reason why only 19 messages exist is because the manual notes one as a "spare channel".
So this is an incomplete set of audio clips. The files are distributed as stereo variable bit rate Ogg format. This makes me think whoever recorded these has very little experience in preserving audio. For clips this short, lossless compression is almost certainly appropriate. The original system is also definitely a single channel tape recording. But I'll get more into the history of this later. To my knowledge, this is the only digital recording available of the voice warning system.
Restoration
I listened to the clips indvidually. All of the clips have a clearly identifiable female human voice in them. The quality is quite poor with some odd distortion and tape hiss however. I created a spectrogram of the "Engine Oil Quantity Low" recording
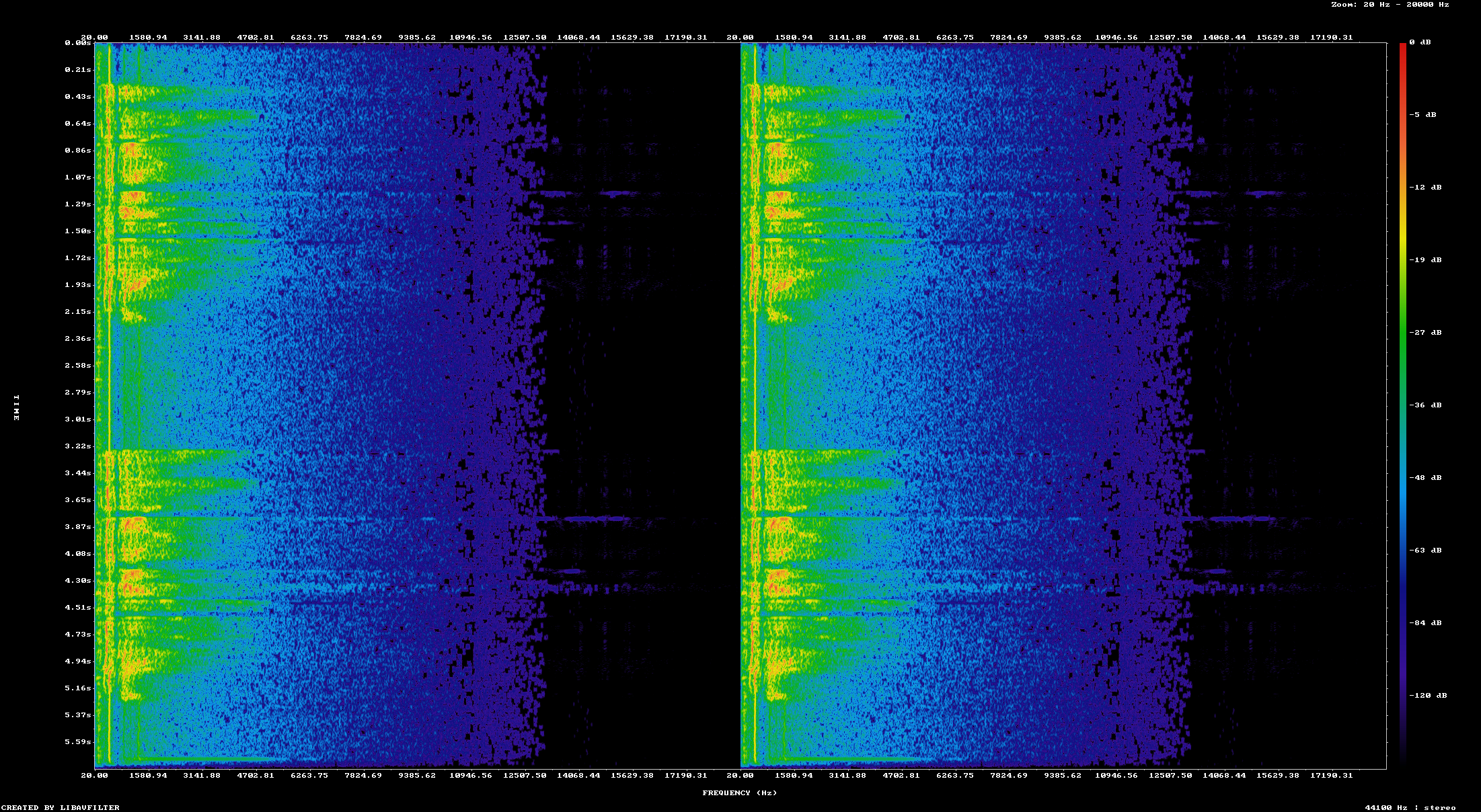
This appears to be in fact a mono recording with both channels identical. There is also practically no recorded signal above 5000 Hz, with almost all signal above that being 20 dB below the voice signal. I split the two channels into wave files by running ffmpeg -i EngineOilQuantityLow.ogg -map_channel 0.0.0 left.wav -map_channel 0.0.1 right.wav. In examining the two files it appears the recorded audio is actually two unique audio tracks. Practically speaking I can't discern an audible difference between the two. The actual difference may have somethng to do with the fact that I've converted a lossy format back to a lossless format. I decided that going forward I'd just analyze only the left audio track of each file.
Looking at just the left audio track of "Engine Oil Quantiy Low" over a range of 20-6000 Hz shows us this
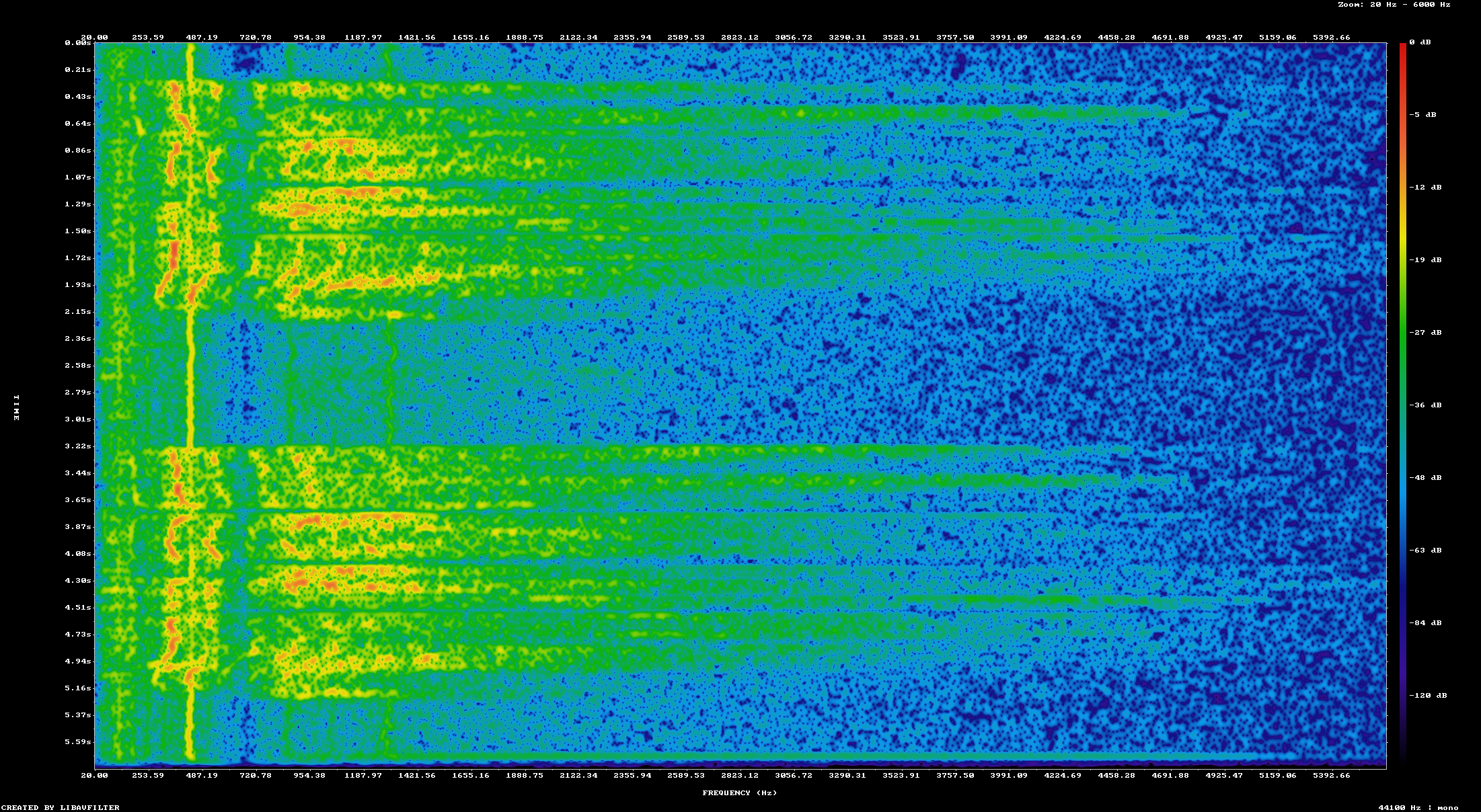
There are a few things to note here
- Several sections appear in red, this means they are "0 dB" which indicates a maximum audio level. This is why the recording is distorted
- There is a huge amount of noise showing up around 440 Hz that is certainly not part of the original recording.
- Since this audio includes human speech there is some silence. During those time, a noise pattern is very visible
- There is practically no audio signal around 700 Hz. It is almost a deadspot in the recording
Computing a noise signature
There is to my knowledge no general algorithm to remove noise from an audio sample. The only way to do this would be to have a separate recording of only the noise, which we obviously do not have here. In the case of these recordings I suspect there are multiple sources of noise. I can think of several including the degradation of the magnetic tape, the method which was used to digitize the analog recordings & possibly some noise in the original recording studio. Since I don't have an exact representation of the noise in the audio I'll need to find a way to approximate it. As it turns out each audio clip is the same voice message played twice with a long pause between them. This allows me to make several assumptions about the audio recorded during the pause
- The pause should be total silence
- Any audio detected during the pause is only noise
- The same noise is present when human voice is present
So what I set out to do was to use the pause to characterize the noise and then apply the observations from that to remove noise in the original audio. What I did was use numpy to compute the FFT of all the available audio samples from the pause of "Engine Oil Quantity low" warning audio. That showed me this
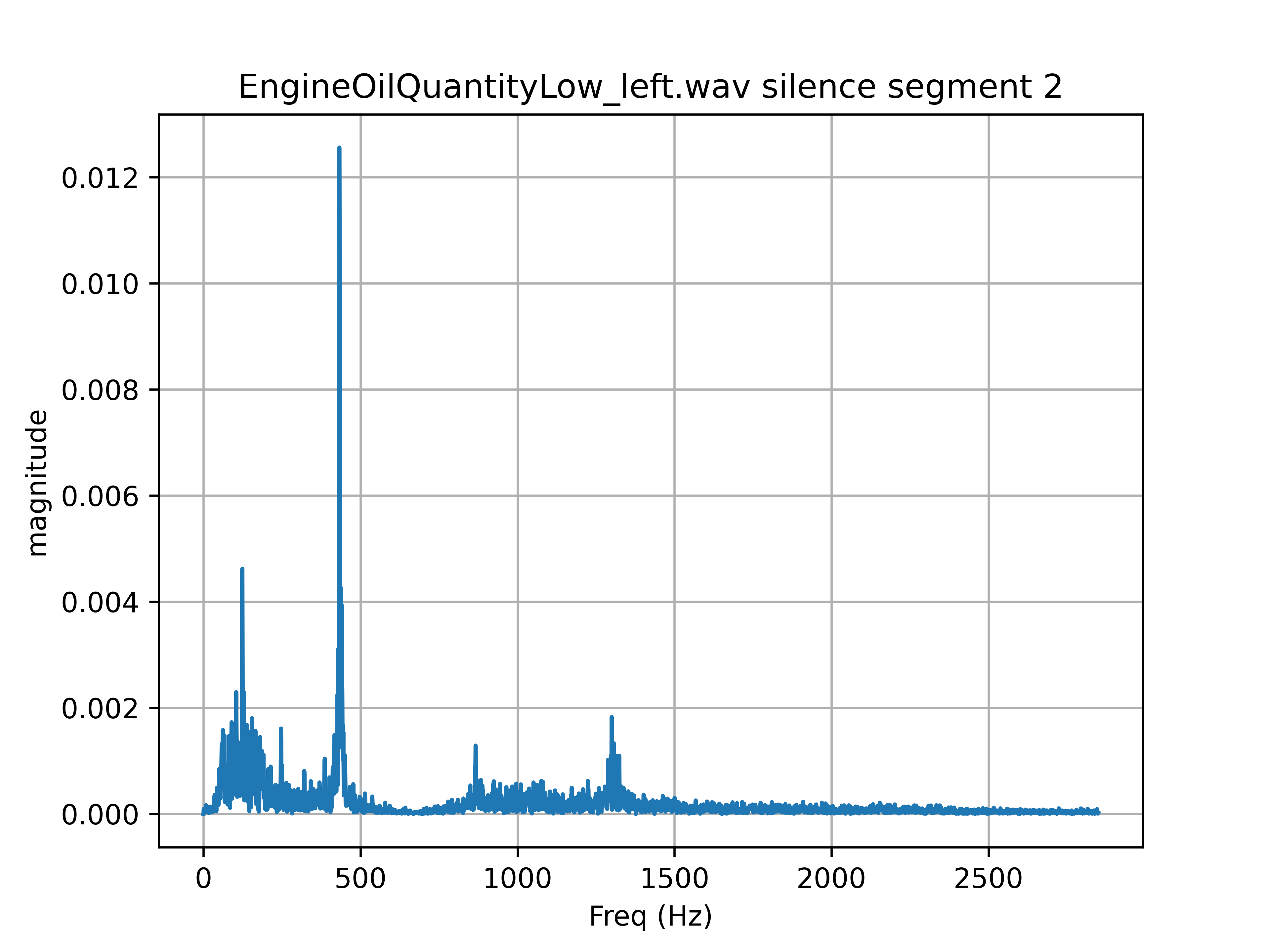
The magnitude in this relative to the total power available, so the scale is not really that important. You can see that there is a huge peak below 500 Hz. There are some other easily identifiable peaks. This is very promising as it means the noise is concentrated around certain frequencies. The next step was to identify the frequencies somehow. Since I already had the FFT, I sorted the bins by the absolute power contained in each bin. This gives me the most powerful signals in descending order. However, each bin represents only a tiny sliver of the total power in the spectrum. I don't want to wind up with dozens or hundreds of components to my noise signature.
To compute the highest power noise ranges what I did was search between the FFT bins between 260 Hz and 2850 Hz. I selected the highest power 2.5% of bins. In order to reduce this into something usable the first thing I did was merge all adjacent bins together. So instead of having a list of FFT bins, I wind up with a range of FFT bins. This reduces the total number of sources but not by enough to be practical. I then further merged all the remaining bin ranges together based on the following criteria:
- if the adjacent bin ranges are separated by less than 1/2 the bandwidth of the current bin range, merge them
- if the adjacent bin ranges are separated by less than 20 Hz, merge them.
After performing the above merge steps I generated the same graph of the FFT but with the sections identified as noise shaded in red.
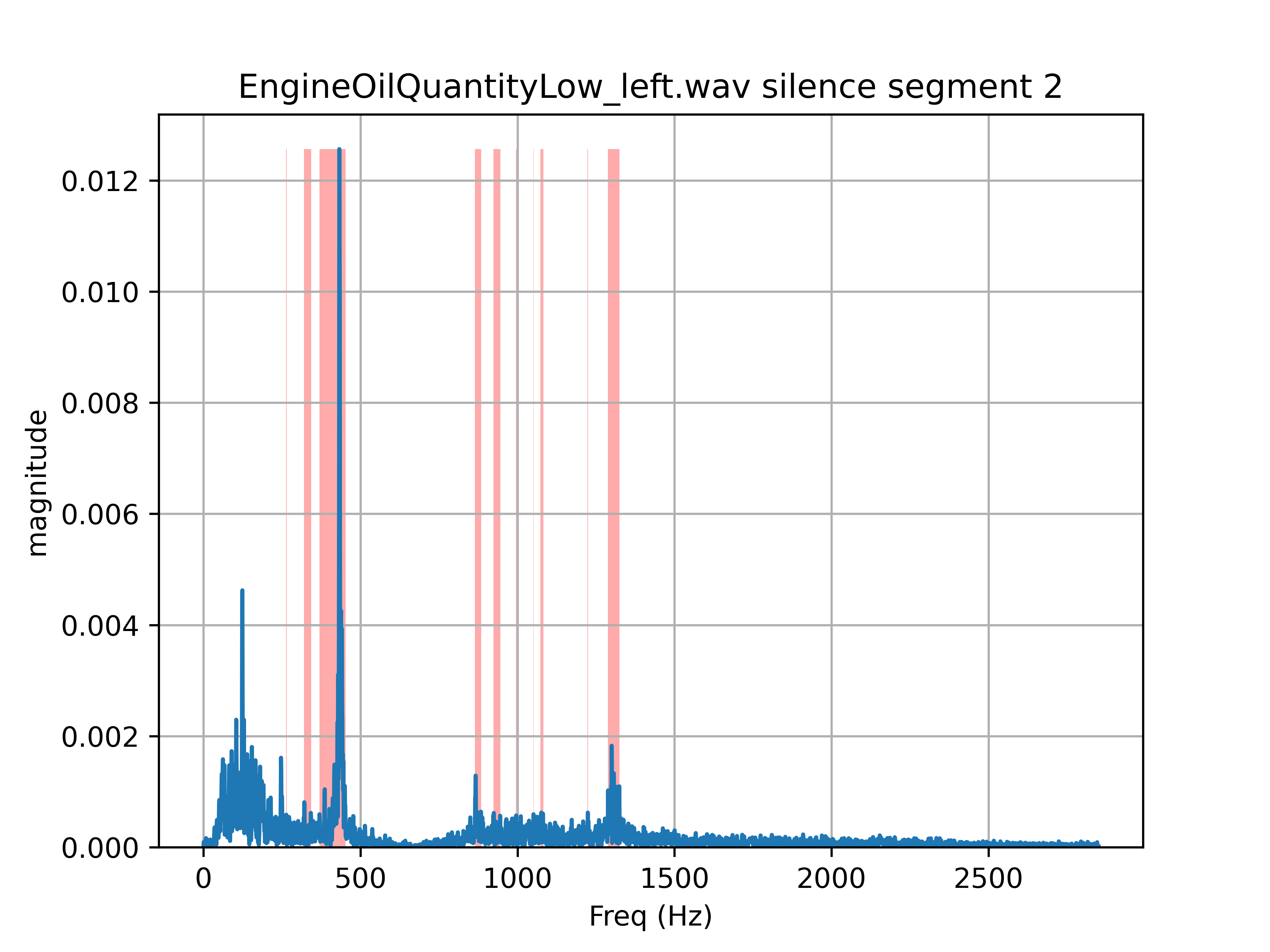
This produces a bunch of wide audio frequency ranges that are centered directly on top of the noise peaks in the FFT. So this is exactly what I was looking for. There are some other ranges identified in there as well but that is dealt with later.
The next step was to use these audio frequency ranges to filter the actual human voice in the audio. My initial attempt at doing this was simply to compute an FFT of the entire audio signal and set some of the bins to zero. This kind of works but causes a bunch of issues and can actually create noise at other frequencies. So instead what I did was build a set of Butterworth bandstop filters using Scipy's IIR filter computation code. What this does is compute a set of values representing a infinite impulse response filter. This can then applied to an audio signal. You can actually produce a plot of each filter's frequency response.

This example plot shows us that a specific filter has a huge amount of signal attenuation around the large noise source visible in the FFT we looked at earlier. Signals at other frequencies pass through with little to no attenuation. Applying this filter to the entire recording removes the noise but also removes the human voice at the same frequency. But thankfully human voice is spread out over a wide range of frequencies. So removing a narrow range of frequencies is usually called a notch filter and actually improves the overall clarity of the audio signal. The filters are applied to the signal sequentially one after the other.
One of the issues I ran into during this was that some of the filters had a frequency response plot that was basically flat. The point of maximum attenuation was sometimes insignificant at only 3 dB or so. So any filter that didn't generate at least 20 dB of attenuation I skipped applying. I'm not an expert at digital filters but my understanding is that applying any such filter always has drawbacks. So I chose to skip applying some filters that shouldn't generate much difference in the output audio anyways. My intent is skipping this avoids degradation in an otherwise un-needed step.
Other techniques for noise reduction
I also applied a high pass filter passing all signals above 260 Hz then a low pass filter passing all signals below 2850 Hz. This reduces the audio signal outside the range of normal human voice, which is probably just noise anyways.
The final trick I applied to this was to lower the audio level during the silence segments. After all, they are supposed to be silent. To avoid creating any harsh pops in the audio I used a window based on the sine function to taper the audio level down over 250 milliseconds. During the middle of the silence segment I attenuated the signal by 6 to 12 dB based off a random number generator. When the silence segment ends I use the same 250 milliseconds window based on the cosine function to taper the audio back up to normal amplitude.
Boosting low frequency
I looked at the spectrogram of almost every source file. The signal between 610 Hz and 710 Hz is very low, but present. I decided that this is not intentional and wanted to boost it back up. I did this by filtering the entire clip using a bandpass filter over that frequency range. This gives me an audio clip that is the same length but with only the signal in that frequency range. I then multiplied that signal by 4 and added back into the original audio clip. The net result of this is to apply gain to that narrow frequency of audio ranges. This does come with the downside of potentially boosting any noise in that frequency range. Doing this reduces the bit resolution of the audio by a factor of a little more than 2 bits. Since the source audio is variable bit rate I don't think this matters at all.
Results
The same overall technique was applied to all the audio clips. I think the one that sounds the best is the "Primary Hydraulic Pump Failed" clip. You can see the before and after of the spectrogram here
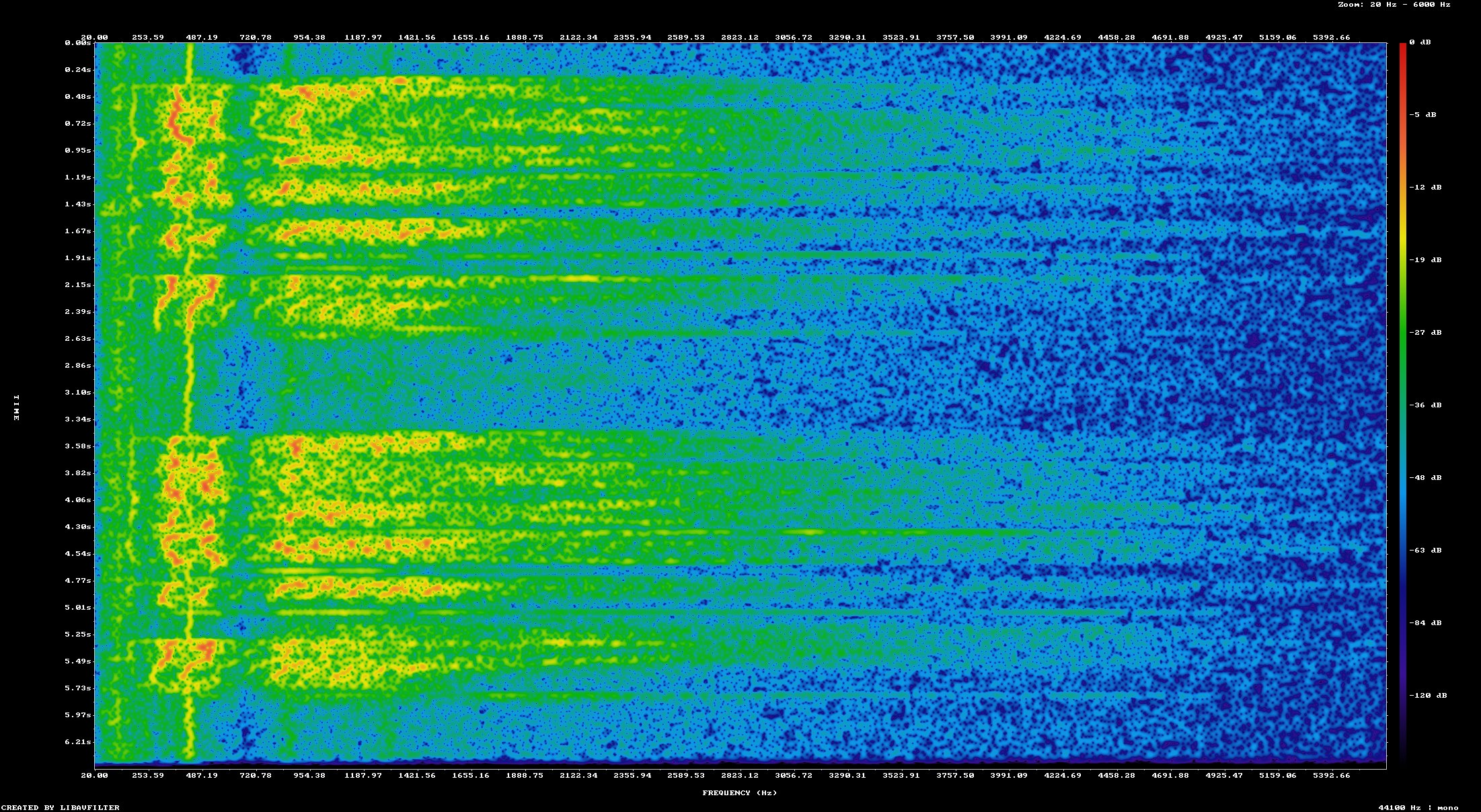
The spectrogram of the "Hydraulic Pump Failed" clip before
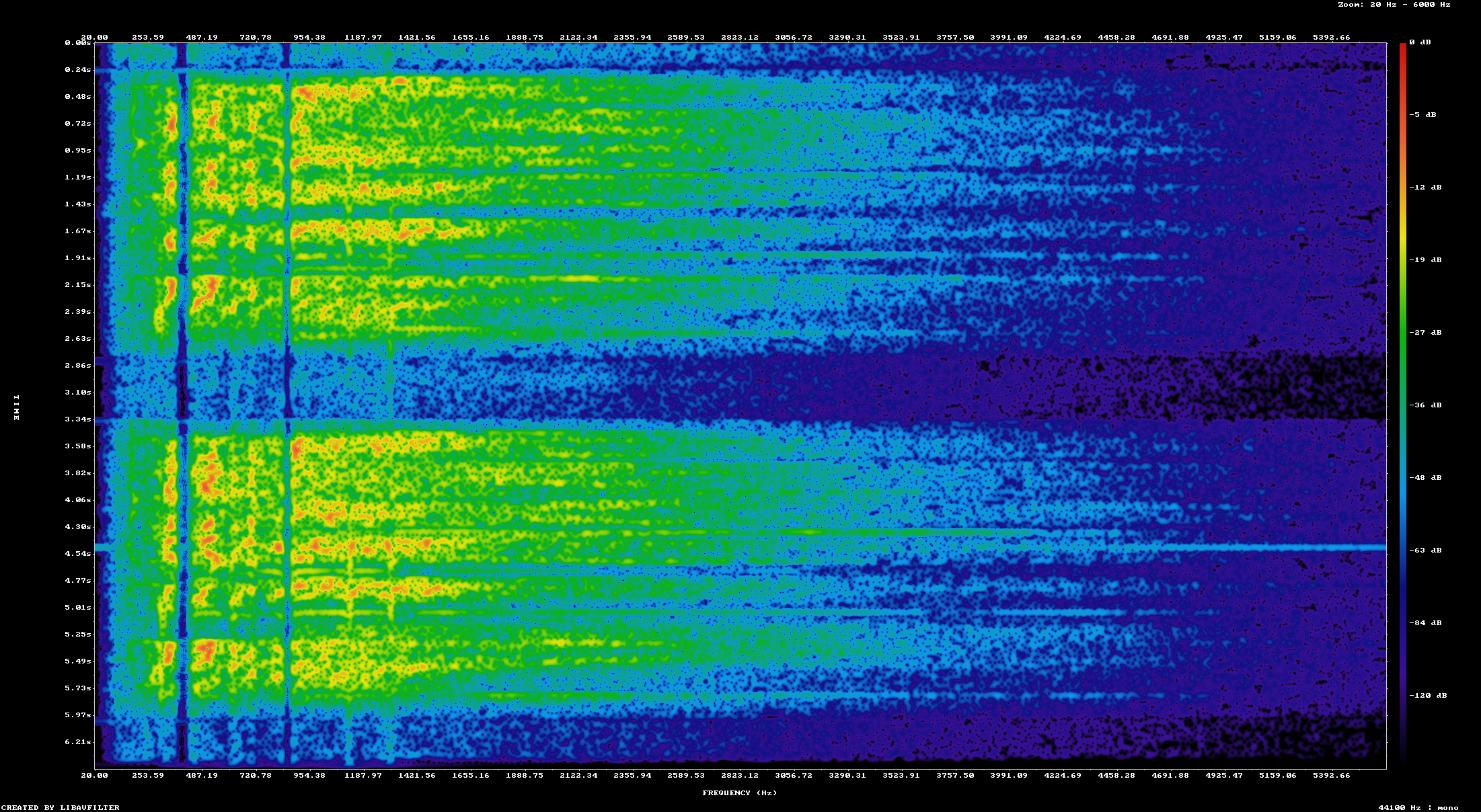
The spectrogram of the "Hydraulic Pump Failed" clip after denoising
The denoised clip clearly shows the notch filters that were applied to remove several large noise sources in the recording. All of the clips sound better to me, but not all of them are great.
You can download all the restored audio here in a ZIP file as well as a Python program containing the code I used to perform the restoration
Provenance
I think these recordings were obtained by getting an original voice warning system back to a functional state and then playing each recording one by one. The B-58 flight manual states "The malfunction an indicator light and voice warning system test button is used to check the voice warning system. Depressing this button will start the voice warning system transmitting the highest priority message. The override button or the master warning or caution lamp may then be used to check each message in order". This sounds like the system can easily be instructed to play each message.
Given that the files are stereo audio (the original would almost certianly be mono) compressed in a VBR format, I think these were made by gaining access to a B-58 & powering up the cockpit with an external power supply. Someone then held a handheld recording device (or probably their cell phone) near the pilot's headset. At that point the system was commanded to play each message one at a time. An additional fact in support of this is the fact that almost all the files have no significant component of audio around 700 Hz. This probably means that either the headset speaker had no response at that frequency or more likely the microphone did not.
So this leads me to my last question: Who is it that we are listening to? A quick search around the internet provides a common answer: Joan Elms. I don't really know who Joan Elms is so I looked up her IMDB page. Apparently she was a voice performer and is also uncredited in at least one film as an acrtress. The IMDB page even mentions "Recorded for Nortronics Division of Northrop Corporation the automated voice warnings used on the Convair B-58 "Hustler" bomber aircraft." You can find dozens of web pages including Wikipedia mentioning this.
The problem with this, I have literally no idea who Joan Elms is. There is no information on her at all. I can't find statements from Elms, her publicist or anyone indicating she is the voice we hear. It's all secondhand sources that seem to just cite each other. But if we go the July 1962 edition of Popular Science we are greeted by this on page 76

Pictured is Gina Drazin, who was a secretary at Northrop at the time. Later pages in the same issue state 12 women's voices were tried along with at least 6 men's. Ultimately, Gina Drazin became the voice of the B-58. This is documented in a contemporary source, which I consider to be much more reliable than an IMDB page.
But if that isn't enough for you, in 2016 the Washington Post ran a piece which Gina Drazin was interviewed for along with her husband. So that is two primary sources separated by 54 years both interviewing the same individual.
I'll quickly mention autiobiographical accounts should always be scrutinized. But I find it highly unlikely that a secretary for a defense contractor like Northrop would be able to pass herself off as something she was not in the 1960s. It was not even until 1974 in the United States that women were allowed to open a bank account on their own. What possible reason would Drazin have for this anyways? So to me that settles it, Joan Elms is most definitely not the voice of the B-58. It is Gina Drazin.
Unfortunately Gina Drazin passed away in 2022. So I can't reach out to her but I can at least set the record straight.
It is entirely possible however that Joan Elms voice was recorded to be the voice of the B-58 but was never selected.