Making WSJT-X decoding functions thread safe
In my previous blog post I worked on developing a wrapper to call the WSJT-X decoding function for the FT-8 mode from C. I took steps to make sure that I did not introduce any thread-safety issues. However, I was more or less aware that the underlying Fortran code is not actually thread safe. When I tried to use my wrapper from multiple threads in the same program, the program crashed. When I ran the program using a debugger I got a backtrace like this after a crash
#0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=140737305904704) at ./nptl/pthread_kill.c:44
#1 __pthread_kill_internal (signo=6, threadid=140737305904704) at ./nptl/pthread_kill.c:78
#2 __GI___pthread_kill (threadid=140737305904704, signo=signo@entry=6) at ./nptl/pthread_kill.c:89
#3 0x00007ffff6e42476 in __GI_raise (sig=sig@entry=6) at ../sysdeps/posix/raise.c:26
#4 0x00007ffff6e287f3 in __GI_abort () at ./stdlib/abort.c:79
#5 0x00007ffff6e89676 in __libc_message (action=action@entry=do_abort, fmt=fmt@entry=0x7ffff6fdbb77 "%s\n") at ../sysdeps/posix/libc_fatal.c:155
#6 0x00007ffff6ea0cfc in malloc_printerr (str=str@entry=0x7ffff6fdec48 "malloc(): unsorted double linked list corrupted") at ./malloc/malloc.c:5664
#7 0x00007ffff6ea42dc in _int_malloc (av=av@entry=0x7fffd4000030, bytes=bytes@entry=528) at ./malloc/malloc.c:4010
#8 0x00007ffff6ea4d4f in _int_memalign (av=av@entry=0x7fffd4000030, alignment=alignment@entry=32, bytes=bytes@entry=456) at ./malloc/malloc.c:4968
#9 0x00007ffff6ea5cdf in _mid_memalign (address=<optimized out>, bytes=456, alignment=32) at ./malloc/malloc.c:3570
#10 __GI___libc_memalign (alignment=32, bytes=456) at ./malloc/malloc.c:3525
#11 0x00007ffff7223459 in fftwf_malloc_plain () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#28 0x00007ffff7316339 in fftwf_mkapiplan () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#29 0x00007ffff731d929 in fftwf_plan_many_dft_r2c () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#30 0x00007ffff731cdb9 in fftwf_plan_dft_r2c () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#31 0x00007ffff731ccc7 in fftwf_plan_dft_r2c_1d () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#32 0x00007ffff731766c in sfftw_plan_dft_r2c_1d_ () from /lib/x86_64-linux-gnu/libfftw3f.so.3
#33 0x0000555555572da0 in four2a (a=..., nfft=3840, ndim=1, isign=-1, iform=0) at ../lib/four2a.f90:79
#34 0x000055555558b53f in sync8 (dd=<error reading variable: value requires 720000 bytes, which is more than max-value-size>, nfa=200, nfb=4007, syncmin=1.60000002, nfqso=1500, maxcand=600, nzhsym=50, candidate=..., ncand=0, sbase=...) at ../lib/ft8/sync8.f90:39
#35 0x0000555555575f51 in ft8_decode::decode (this=..., callback=callback@entry=0x5555555a956b <mycallback>, iwave=..., nqsoprogress=0, nfqso=1500, nftx=0, newdat=.TRUE., nutc=0, nfa=200, nfb=4007, nzhsym=50, ndepth=1, emedelay=0, ncontest=0, nagain=.FALSE.,
lft8apon=.FALSE., lapcqonly=.FALSE., napwid=75, mycall12=..., hiscall12=..., ldiskdat=.FALSE., _mycall12=12, _hiscall12=12) at ../lib/ft8_decode.f90:197
#36 0x0000555555574479 in decode_ft8_shim (callback={void (void)} 0x5555555a956b <mycallback>, id2=..., nqsoprogress=0, nfqso=1500, nftx=0, newdat=.TRUE., nutc=0, nfa=200, nfb=4007, nzhsym=50, ndepth=1, emedelay=0, ncontest=0, nagain=.FALSE., lft8apon=.FALSE.,
lapcqonly=.FALSE., napwid=75, mycall=..., hiscall=..., ndiskdat=.FALSE., _mycall=12, _hiscall=12) at ../shims/ft8_shim.f90:46
#37 0x00005555555a9f5d in decode_ft8 (params=params@entry=0x7fffffffcd40, outputArray=outputArray@entry=0x7ffff51ffd80) at ../decode_ft8.c:550
#38 0x00005555555ac0ee in decoder_worker_main (d=0x7fffffffccf8) at ../interactive_ft8.c:146
#39 0x00007ffff6e94ac3 in start_thread (arg=<optimized out>) at ./nptl/pthread_create.c:442
#40 0x00007ffff6f26850 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
From this stack trace I was able to observe that the crash happened somewhere while sfftw_plan_dft_r2c_1d_ was being called from the WSJT-X fortran code. This function is part of the Fortran wrapper for FFTW3. After doing some reading on the documentation of FFTW3 it became apparent that this is not thread safe. FFTW3 is a library for computing fast fourier transforms. Any execution of an FFT requires the creation of a "plan" before the actual FFT can be executed. The execution of the FFT is thread safe but the creation of the plan is not thread safe. With this knowledge in hand I set out to make the creation of the plan to be thread safe.
From looking at the FT8 decoding code, all of the FFTs are computed inside of a single subroutine called four2a. My initial assumption was this function is some sort of thin wrapper around FFTW3. I've copied the original implementation here and omitted some of the comments for brevity
subroutine four2a(a,nfft,ndim,isign,iform) use fftw3 parameter (NPMAX=2100) !Max numberf of stored plans parameter (NSMALL=16385) !Max half complex size of "small" FFTs complex a(nfft) !Array to be transformed complex aa(NSMALL) !Local copy of "small" a() integer nn(NPMAX),ns(NPMAX),nf(NPMAX) !Params of stored plans integer*8 nl(NPMAX),nloc !More params of plans integer*8 plan(NPMAX) !Pointers to stored plans logical found_plan data nplan/0/ !Number of stored plans common/patience/npatience,nthreads !Patience and threads for FFTW plans save plan,nplan,nn,ns,nf,nl if(nfft.lt.0) go to 999 nloc=loc(a) found_plan = .false. do i=1,nplan if(nfft.eq.nn(i) .and. isign.eq.ns(i) .and. & iform.eq.nf(i) .and. nloc.eq.nl(i)) then found_plan = .true. exit end if enddo if(i.ge.NPMAX) stop 'Too many FFTW plans requested.' if (.not. found_plan) then nplan=nplan+1 i=nplan nn(i)=nfft ns(i)=isign nf(i)=iform nl(i)=nloc ! Planning: FFTW_ESTIMATE, FFTW_ESTIMATE_PATIENT, FFTW_MEASURE, ! FFTW_PATIENT, FFTW_EXHAUSTIVE nflags=FFTW_ESTIMATE if(npatience.eq.1) nflags=FFTW_ESTIMATE_PATIENT if(npatience.eq.2) nflags=FFTW_MEASURE if(npatience.eq.3) nflags=FFTW_PATIENT if(npatience.eq.4) nflags=FFTW_EXHAUSTIVE if(nfft.le.NSMALL) then jz=nfft if(iform.le.0) jz=nfft/2+1 aa(1:jz)=a(1:jz) endif if(isign.eq.-1 .and. iform.eq.1) then call sfftw_plan_dft_1d(plan(i),nfft,a,a,FFTW_FORWARD,nflags) else if(isign.eq.1 .and. iform.eq.1) then call sfftw_plan_dft_1d(plan(i),nfft,a,a,FFTW_BACKWARD,nflags) else if(isign.eq.-1 .and. iform.eq.0) then call sfftw_plan_dft_r2c_1d(plan(i),nfft,a,a,nflags) else if(isign.eq.1 .and. iform.eq.-1) then call sfftw_plan_dft_c2r_1d(plan(i),nfft,a,a,nflags) else stop 'Unsupported request in four2a' endif if(nfft.le.NSMALL) then jz=nfft if(iform.le.0) jz=nfft/2+1 a(1:jz)=aa(1:jz) endif end if call sfftw_execute(plan(i))
After some analysis I was able to determine what this function does is this
- Gets the memory address of
aas an integer and stores it innloc. This is imilar to anintptr_tin C - Searches all the existing plans for matching values of
nfft,isign,iformandnloc - If the plan does not match, it calls the appropriate FFTW3 wrapper subroutine to create a plan. The plan is stored in the arrays
nn,ns,nf,nl. - It then executes the plan
The only reason this works is because the variables used for storing existing plans are declared with a save statement that makes them persistent. So I identified that I need to provide this same functionality somehow without all the thread safety issues. This where this project started
Fortran's save, common, and data statements
I was not very familiar with Fortran before this so I was rather confused as to how assigning these plans to variables in nn, ns, nf, & nl had any effect. They appear to be subroutine local variables. But I noticed in addition to those variables being declared there is also the statement save plan,nplan,nn,ns,nf,nl. The save statement does basically what it sounds like. It ensures that the value of a local variable in a subroutine is persisted from one call to the next. This in my mind is superficially similar to declaring a variable as static in C. But I was curious to see how this is implemented.
example_save.f90 322 Bytes
subroutine sub_save_stmt(x) use iso_c_binding, only: c_int32_t integer(c_int32_t) x integer(c_int32_t) y save y y = y + 10 x = y end program example use iso_c_binding, only: c_int32_t integer(c_int32_t) i integer(c_int32_t) j do i=1,4 call sub_save_stmt(j) print *, ' j = ', j enddo end
This example program when run produces this output
j = 10 j = 20 j = 30 j = 40
The variable y in the subroutine sub_save_stmt is incremented by 10 each call and saved. Due to Fortran's implementing parameters as pass by pointer, the value of j is changed in the caller and printed out.
The Fortran data statement is almost identical in implementation to save, but it allows a variable to be initialized to a specified value when the program starts. The common statement is another variation on this. The common statement reserves spaces so a variable in subroutine is persisted, but it does so with a named prefix. This allows two otherwise unrelated subroutines to share the same storage space for the same peristent variables.
All of these statements are used in the four2a subroutine and nothing about the subroutine is thread safe. So I needed to refactor out all of this. The memory segments reserved by the Fortran compiler wind up being shared and accessed by all threads simultaneously and left in an ultimately invalid state.
Creating a decoding context
The only way I could think of to refactor this to be thread safe was to implement what I decided to call a "decoding context". This is just a type that I can pass through the entire call stack from where my C wrapper starts to invoke the decoding code to where four2a is invoked. This decoding wrapper can be used to store all the necessary FFTW3 plans for executing FFTs. I also decided to make this decoding context only executed pre-planned FFTs. This is required because the underlying FFTW3 library does not permit multiple threads to invoke the planning subroutines in parallel.
So I declared a type like this in Fortran
type :: planned_fftw ! FFTW3 fortran interface always uses this type as the type for plans ! https://stackoverflow.com/a/24082216 integer*8 :: plan; integer :: isign; integer :: iform; integer :: nfft; complex, dimension(:), pointer :: dataset; end type planned_fftw type :: decode_context type(planned_fftw), dimension(:), pointer :: plans; integer :: numplans; end type decode_context
The decode_context type has a dynamically allocated array plans that stores the already planned FFTs. I was initially concerned I would need to preplan a huge number of FFTs, but after instrumenting the code paths I determined I only needed to handle seven unique FFTs. One difference I implemented was each FFT has its own dynamically allocated array of data to be used as both the input and output. The FFTW3 library requires each and every planned FFT to point a specific memory region that is defined in advance of the FFT execution. The original four2a function computed a unique FFTW3 plan for each memory location. This seems needlesly complex as I can just copy the values into the memory region beforehand and copy the computed values back out afterwards. So I implemented the subroutines preplan_four2a and execute_planned_four2a. The original four2a subroutine basically just became a wrapper around execute_planned_four2a with an extra context argument.
Implementing execute_planned_four2a wound up with a very particular implementation. Fortran 90 does not validate the types associated with arguments when a subroutine is invoked unless you explicitly ask it to. The argument a in the original four2a implementation was notionally declared as complex a(nfft). In reality, this argument is passed as a pointer to an array of either complex or real because it just gets passed into the various planning functions of FFTW3. FFTW3 has no complaint processing any region of memory it can read. So I needed to somehow reimplement this pecuilar fact while using a dynamically allocated array if I wanted to make execute_planned_four2a a drop in replacement for four2a. What I ended up doing was declaring both the dynamically allocated array as complex and the argument as complex. Then I used a loop to copy the data in & another loop to copy the data back out. The complex type in Fortran is implemented internally as two real values from what I can see. So this has the desired behavior in all cases. This may run afoul of some implementation or architecture specific behavior in the future but it isn't a new problem if it is.
The inexplicable part of the original four2a subroutine was the local variable named aa. All this seemed to be used for was storing a copy of the data before executing the planned FFT and then copying that back afterwards. I thought this did something important but eventually realized this probably doesn't do anything. It definitely appears that it does, but this only ever would execute when the FFT is planned. This would only be on the first invocation of four2a. I omitted this from my implementation entirely. I did of course want to understand why this was present in the first place. The earliest commit I could find with this code had this description
commit 9e73f8721831dab56cabbef51d7b26b301342b9b
Author: Joe Taylor <k1jt@arrl.org>
Date: Tue May 22 14:28:39 2012 +0000
Major changes to the MAP65 branch. This branch is now a copy of
MAP65 v2.3.0, r631, as checked out from the SVN repository on
pulsar.princeton.edu. If all goes well with this commit, subsequent
MAP65 development will use the Berlios repository.
I don't have access to whatever internal resource at Princeton this was. So I have no idea as to the history of this.
Refactoring out the other save, data, and common statements
While working on the refactor of the FFTW3 invocation I had learned what the save, data, & common statements do in Fortran. It stands to reason that if the authors of WSJT-X used those in one subroutine they probably used it elsewhere. In fact, it is used all over the place. I started hunting down all the usages and managed to put them in three categories
- decoding tables, which are just precomputed values. In this case they are computed on the first invocation of a
subroutinein the Fortran code. - persistent data, that is stored from one invocation to the next
- various constants
The decoding tables are various large arrays of data that are computed completely independent of subroutine parameters on the first invocation. Since the parameters have no impact on the values in the arrays I was able to lift the computation of this tables and move them into completely separate subroutines. These are called as part of the decoding context initialization. An example of this is from the subroutine subtractft8
! originally from subroutine subtractft8 in ft8/subtractft8.f90 if(first) then ! Create and normalize the filter pi=4.0*atan(1.0) fac=1.0/float(nfft) sumw=0.0 do j=-NFILT/2,NFILT/2 window(j)=cos(pi*j/NFILT)**2 sumw=sumw+window(j) enddo cw=0. cw(1:NFILT+1)=window/sumw cw=cshift(cw,NFILT/2+1) call four2a(cw,nfft,1,-1,1) cw=cw*fac first=.false. do j=1,NFILT/2+1 endcorrection(j)=1.0/(1.0-sum(window(j-1:NFILT/2))/sumw) enddo endif
This code populates the array endcorrection the first time the subroutine is invoked. Interesting this is actually done by calling four2a, the function I had already refactored.
The second case is persistent data. This was refactored by just pre-allocating large arrays, storing them on the context and then using them in the subroutine. In general it is hard to figure out exactly why these arrays are persisted, but I opted to avoid making changes to the implementation without a complete understanding of how the decoding functions.
There were no shortage of various constants that were declared with an associated data statement. In all cases I just refactored these to be assignment statements to regular arrays that are local in scope to the subroutines. One common occurrence was this code snippet
integer icos7(0:6) data icos7/3,1,4,0,6,5,2/ !Costas 7x7 tone pattern
The array icos7 is initialized with a data statement. This means an area of shared memory is used to persist it. This was just changed to be an array initializer. There is a performance penalty for doing this but I don't consider it significant enough to address.
Refactoring out module variables and Fortran "equivalence" statements
Although I was very confident that my previous refactors were effective, it was also apparent there was some region of memory being shared. Running valgrind --tool=helgrind produced this output
==141310== Possible data race during write of size 8 at 0x43E8C0 by thread #2 ==141310== Locks held: none ==141310== at 0x15B98B24: memset (in /usr/libexec/valgrind/vgpreload_helgrind-amd64-linux.so) ==141310== by 0x13C65D: sqf.0 (subtractft8.f90:71) ==141310== by 0x13D400: subtractft8_ (subtractft8.f90:46) ==141310== by 0x149926: ft8b_ (ft8b.f90:445) ==141310== by 0x131C2B: __ft8_decode_MOD_decode (ft8_decode.f90:224) ==141310== by 0x12C52C: decode_ft8_shim_ (ft8_shim.f90:50) ==141310== by 0x16AA4C: decode_ft8 (decode_ft8.c:857) ==141310== by 0x16AD87: decoder_worker (decode_ft8.c:787) ==141310== by 0x15B9396A: ??? (in /usr/libexec/valgrind/vgpreload_helgrind-amd64-linux.so) ==141310== by 0x166F4AC2: start_thread (pthread_create.c:442) ==141310== by 0x16785A03: clone (clone.S:100) ==141310== ==141310== This conflicts with a previous write of size 8 by thread #3 ==141310== Locks held: none ==141310== at 0x15B98B24: memset (in /usr/libexec/valgrind/vgpreload_helgrind-amd64-linux.so) ==141310== by 0x13C65D: sqf.0 (subtractft8.f90:71) ==141310== by 0x13D400: subtractft8_ (subtractft8.f90:46) ==141310== by 0x149926: ft8b_ (ft8b.f90:445) ==141310== by 0x131C2B: __ft8_decode_MOD_decode (ft8_decode.f90:224) ==141310== by 0x12C52C: decode_ft8_shim_ (ft8_shim.f90:50) ==141310== by 0x16AA4C: decode_ft8 (decode_ft8.c:857) ==141310== by 0x16AD87: decoder_worker (decode_ft8.c:787) ==141310== Address 0x43e8c0 is 0 bytes inside data symbol "equiv.0.1"
Fortran supports a contains statement that allows you to do things such as nesting a function inside of a subroutine. You can also place variables inside a Fortran module and access them from subroutines within the same module. As it turns out this shares variables from the outer subroutine to the inner function implicitly. This also means that those variables use static storage, at least in some cases. What I did was just refactor the nested function not to be nested and to take all the previously shared variables as arguments. After this refactoring running the helgrind tool again produced this output.
==192922== Possible data race during write of size 4 at 0x43E8C0 by thread #3 ==192922== Locks held: none ==192922== at 0x13CA41: subtractft8_sqf_ (subtractft8.f90:42) ==192922== by 0x13D923: subtractft8_ (subtractft8.f90:112) ==192922== by 0x149D63: ft8b_ (ft8b.f90:445) ==192922== by 0x131C2B: __ft8_decode_MOD_decode (ft8_decode.f90:224) ==192922== by 0x12C52C: decode_ft8_shim_ (ft8_shim.f90:50) ==192922== by 0x16AE89: decode_ft8 (decode_ft8.c:857) ==192922== by 0x16B1C4: decoder_worker (decode_ft8.c:787) ==192922== by 0x15B9396A: ??? (in /usr/libexec/valgrind/vgpreload_helgrind-amd64-linux.so) ==192922== by 0x166F4AC2: start_thread (pthread_create.c:442) ==192922== by 0x16785A03: clone (clone.S:100) ==192922== ==192922== This conflicts with a previous write of size 4 by thread #2 ==192922== Locks held: none ==192922== at 0x13CA41: subtractft8_sqf_ (subtractft8.f90:42) ==192922== by 0x13D923: subtractft8_ (subtractft8.f90:112) ==192922== by 0x149D63: ft8b_ (ft8b.f90:445) ==192922== by 0x131C2B: __ft8_decode_MOD_decode (ft8_decode.f90:224) ==192922== by 0x12C52C: decode_ft8_shim_ (ft8_shim.f90:50) ==192922== by 0x16AE89: decode_ft8 (decode_ft8.c:857) ==192922== by 0x16B1C4: decoder_worker (decode_ft8.c:787) ==192922== by 0x15B9396A: ??? (in /usr/libexec/valgrind/vgpreload_helgrind-amd64-linux.so) ==192922== Address 0x43e8c0 is 0 bytes inside data symbol "equiv.0.0"
This means that some region of memory is still being shared between threads. I decided to analyze the symbols in the compiled object code. I ran nm -A build/subtractft8.o which produced output including the line build/subtractft8.o:0000000000000000 b equiv.0.0. This is caused by the Fortran statement equivalence (x,cx). This symbol disappeared after refactoring out the statement. The equivalence statement had been used to share storage between an array of real and an array of complex values within the same scope. I refactored this to use a dynamically allocated array for the complex data. Fortran has no specific way to cause an array pointer to point at a region of memory with the wrong data type. But you can just use the ISO C bindings present to convert the pointer into a C pointer and then back into a Fortran pointer of whatever type you want. This looks like this in Fortran
mem_block_p = c_loc(cx) ! get the pointer value call c_f_pointer(mem_block_p, x, [NFFT+2]) ! force the real pointer to point at the same space
Running valgrind --tool=helgrind then produced clean output. The interesting thing about this is that this doesn't seem to be a guarantee of the Fortran language. There are other subroutine's with equivalance statements that do not appear to use static storage.
Refactoring out variables the compiler moved to static memory
When I compiled the Fortran code, I kept getting warnings like this
../lib/deep4.f90:13:33: 13 | character*15 callgrid(MAXCALLS) Warning: Array ‘callgrid’ at (1) is larger than limit set by ‘-fmax-stack-var-size=’, moved from stack to static storage. This makes the procedure unsafe when called recursively, or concurrently from multiple threads. Consider increasing the ‘-fmax-stack-var-size=’ limit (or use ‘-frecursive’, which implies unlimited ‘-fmax-stack-var-size’) - or change the code to use an ALLOCATABLE array. If the variable is never accessed concurrently, this warning can be ignored, and the variable could also be declared with the SAVE attribute. [-Wsurprising]
The compiler warning specifically stating "moved from stack to static storage" seemed rather significant. What this means is that the code requested a stack allocated variable but that it is impractically large. The compiler moves it to static storage as a result. Adding the -frecursive switch resulted in these compiler warnings being eliminated but it became apparent that the values allocated on the stack far exceeded normal stack space.
What I did to resolve this was to refactor all these arrays with warnings to be declared as ALLOCATABLE and then allocate a dynamic array. For example the above array was refactored like this
character*15, dimension(:), allocatable :: callgrid allocate(callgrid(MAXCALLS))
Since this array is dynamically allocated it resides on the heap, not the stack. A variable declared as ALLOCATABLE in Fortran is de-allocated as soon as the variable goes out of scope so no manual call to deallocate is required. Dynamically allocating arrays has a performance penalty but I can always address this in the future by finding ways to re-use already allocated memory.
Verifying my solution works
Stage 1: one-to-one comparison of jt9 and express8
After I got to a point where I believed I had a working implementation, I needed a way to verify my solution actually works. Along the way I had frequently tested my code by running with Valgrind to identify memory access issues. So I was relatively confident that it did not crash. The issue with this is that if somewhere along the way I had introduced an error into the decoding logic it could result in a program that was technically safe but not able to decode any messages from the audio stream. So I needed to not only verify my program had no memory access issues but also to verify that it produced output comparable to the original implementation. To gather a test dataset I used my HF receiver to record audio from the frequency 14.074 MHz. This is the internationally used frequency for FT8 on the 20 meter band. I recorded FLAC audio files which are aligned on the FT8 transmission boundaries. I made a total of 19361 recordings. Rather than trying to use them all to do the verification initially I used only 1659 of the files as my dataset.
The jt9 program included with the official WSJT-X distribution can decode FT8 from WAV files. The output is just written to standard output. The input file needs to be a single channel WAV file with a 12000 Hz sample rate and 16 bit audio depth samples. What I did was created a python script to use ffmpeg to convert my FLAC files into WAV files with as 12000 Hz sample rate. I then had jt9 decode the WAV file and parsed the output. I repeated the same thing with express8 and compared the output of both programs. Initially I got a huge number of missing decodes. What I realized was the way that jt9 rounds some of the numeric values is not consistent with what I am doing in express8. So I required the output message to match exactly, but applied the following delta to fields in the decode output
| value | delta |
|---|---|
| dr | 0, -0.1, 0.1 |
| frequency | 0, 1, -1 |
| snr | 0, 1, -1 |
So for any decodes that express8 produces there are actually 27 different outputs of jt9 that I consider a match. After this change to my comparison most of the decodes were matching.
Tracking down and understanding missing decodes
Initially I had 42 messages that express8 could not decode. I found that jt9 adds a1 to the end of some message lines. This seems to be related to something called "AP decoding" also known as a priori decoding according to the manual. I don't think that is actually possible in this case because jt9 is only getting one transmission round, not multiple ones. The jt9 decoder program has this section of code that formats the output lines
annot=' ' if(nap.ne.0) then write(annot,'(a1,i1)') 'a',nap if(qual.lt.0.17) decoded0(37:37)='?' endif
This assigns a variable annot to a string that is just whitespace by default and then in some circumstances assigns it a value. This appears to be written at the end of each line. After ignoring the a1 suffix I was left with 5 decodes that were missing. Those ended with ? a1. I realized this was created by the same section of code when the condition if(qual.lt.0.17) is true. So I ignored that suffix as well since it is not part of the decoded message.
After this change I still had some decodes that did not match. What I did was to run the jt9 program processing the WAV file containing this message using valgrind. valgrind produces heaps of errors like this
==516280== Conditional jump or move depends on uninitialised value(s) ==516280== at 0x11878F: ??? (in /usr/bin/jt9) ==516280== by 0x10EAB0: ??? (in /usr/bin/jt9) ==516280== by 0x10C83E: ??? (in /usr/bin/jt9) ==516280== by 0xCF41D8F: (below main) (libc_start_call_main.h:58)
I knew this to be the case from prior refactoring, but this is real world evidence of the problem. This does not explain why express8 is not able to decode these messages from the same WAV file. All of the missing messages show a very low SNR as reported by jt9. I did consider that the decode was entirely false, that is to say jt9 decodes a message that does not exist at all. Since I have recordings of transmissions from nearby points in time, I looked through those and I see the same call signs being decoded at other times from other recording files. This suggests these are real transmissions that jt9 is decoding. Here is a sample of some of the messages as reported by jt9.
| dr | freq (Hz) | SNR | message |
|---|---|---|---|
| 0.3 | 557 | -15 | CQ V31DL EK57 |
| 0.2 | 2217 | -23 | CQ WB5GM EM10 |
| 0.3 | 596 | -17 | CQ W7FOM DM43 |
| 0.3 | 1160 | -20 | CQ WP4QPZ FK68 |
All of these messages had a very low reported SNR. The transmission in this case must have been received very weakly by my receiver. All of these transmission begin with CQ. What that means is whoever is transmitting them is asking any station anywhere to respond to their transmission. The four digit code at the end is a Maidenhead locator. So we can use this to verify if these transmissions are in anyway reasonable. The transmission CQ WB5GM EM10 comes from a ham radio operator I know and who lives in the same grid square as I do. The callsign W7FQM is registered to ham radio operator in Prescott Valley Arizona. The grid square reported is DM43, which is just to the south of there near Phoenix, Arizona. The callsign WP4QPZ is from a radio operator in Puerto Rico. The same message reports a grid square of FK68 which is right on the island of Puerto Rico. So I believe these are all real messages that jt9 is decoding.
In ft8/ft8b.f90 I found this section of code that is part of subroutine ft8b
if(lapon.or.ncontest.eq.7) then !Hounds always use AP if(.not.lapcqonly) then npasses=4+nappasses(nQSOProgress) else npasses=5 endif else npasses=4 endif if(nzhsym.lt.50) npasses=4 do ipass=1,npasses llrz=llra if(ipass.eq.2) llrz=llrb if(ipass.eq.3) llrz=llrc if(ipass.eq.4) llrz=llrd if(ipass.le.4) then apmask=0 iaptype=0 endif if(ipass .gt. 4) then llrz=llra if(.not.lapcqonly) then iaptype=naptypes(nQSOProgress,ipass-4) else iaptype=1 endif
The variable npasses is an implicit integer variable in Fortran. When the argument to this function lapon is true then npasses is set by reading from the Fortran array nappasses at index nSQOProgressand adding 4 to the result. If lapon is false, then npasses is just set to 4. All of the values in nappasses are positive so npasses is always 4 or more. The loop that uses npasses is actually quite large. It does things like call the subroutine decode174_91 and the subroutine subtractft8. I used valgrind --tool=callgrind to produce output I could visualize with kcachegrind
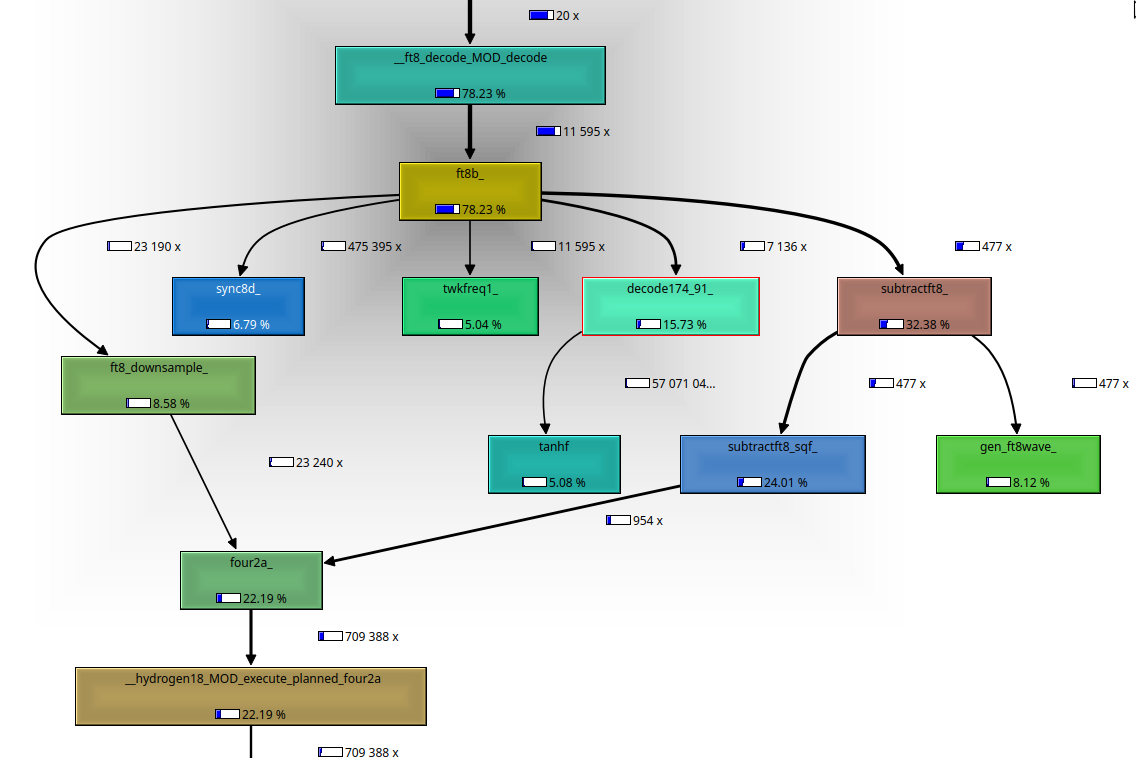
This callgraph shows the approximate callgraph of the ft8b subroutine
This call graph is actually produced by passing express8 25 WAV files to process sequentially but it illustrates the point. In this particular example the subroutine ft8b calls the subroutine decode174_91 7136 times. So obviously multiple passes are necessary to decode messages. My theory was that while the intent of "AP decoding" is to use information from prior transmission to decode the present one the only real effect was to increase the number of passes. To test this what I did was temporarily modified the source code of express8 to run with npasses=8 and to disable the statement if (ipass .gt. 4) that is responsible for selecting the AP decoding behavior in that specific pass. When I did this express8 still could not decode the same set of messages that jt9 can. After doing some analysis I realized that "AP Decoding" basically just guesses some of the bits in the message based off the current configuration when jt9 is run with a single file.
At this point I added an option for "a priori" decoding to express8. In my tests I always enable it, just like jt9 does. All the missing messages were decoded by express8 after this change. I also would like to take the time to point out just how confusing variables are named in the WSJT-X Fortran code. The variables npasses and nappasses have only two letters of difference but do completely different things and are used in a completely different manner.
Stage 2: many-to-one comparison of express8 to itself
The one-to-comparison of jt9 and express8 gave me confidence that express8 was not introducing any major new bugs into the decoding of the FT8 messages. The major point of this project is to refactor the decoder into a library that can be safely loaded into any program and used from multiple threads. I needed a mechanism to confirm that the output was correct even when threads are used. What I did was added a test stage that did the following
- selected a random subset of input files from my test data set
- shuffled the order of the input files
- processed the first input file and compared it to the prior output of
express8 - processed all the input files with a single thread and compared the output to the prior output of
express8 - processed all the input files with enough threads to consume all the host CPU and compared the output to the prior output of
express8 - processed all the input files with four times the number of host CPU of threasd and compared the output to the prior output of
express8
This test was simple to write and incredibly useful. What I found was that the results were incredibly close but commonly differed by just a small number of decodes when multiple files were processed. When threads were involved, the number of differing decodes was slightly higher. From this I concluded that there was still some data being shared somewhere. I went back and traced the call stack of the decoder manually and discovered I have missed a bunch of shared state in the file packjt77.f90. After refactoring out this, the magnitude of the missing decodes changed signficantly. In this case, the differing number of decodes is caused by the "a priori" decoding mechanism. The functionality of "a priori" decoding tries to analyze previous transmissions to effectively guess the value of messages in the present transmission if the signal strength is weak. Since I am processing files in a random order that is not sequential in time this doesn't do anything useful. I would prefer to simply disable this feature but I could not find a way to do that. Since I had already refactored all the shared state used for this decoding feature into my context I just added a new function. This function resets all the shared state to its initial values. It is called directly before each decoding pass when --reset-decode-context is specified on the command line of express8.
This finally got me to outputs that matched exactly regardless of the processing order and number of threads. Doing this test was phenomenally helpful in reproducing bugs.
Stage 3: comparative performance in the presence of signal degradation
The final test I wanted to perform was to comparing the decoding performance of my decoder to the original jt9 program. Since my code is derived from jt9 the performance should be identical. My test files are recorded from real signals so they already contain both very strong and very weak signals. My initial idea for this test was to decode the files, pick a strong signal and then generate interference specifically with that signal. This should work but I concluded it is more complex than needed. What I decided to do was to just generate noise over the entire audio spectrum. I selected a "noise exponent" value that controls the level of attenutation and the level of the noise. Each sample is attentuated then has a noise signal added to it. This adds white noise to the original audio track. The attenutated sample value is computed as \(S_a = S / (N_e^L)\) where \(S\) is the original sample value, \(N_e\) is the noise exponent and \(L\) is the noise level. The noise level increases by one on each iteration. The actual noise is just computed as \(S_n = R * (1.0 - 1 / (N_e^L))\) where \(R\) is a random value in the range \([-1.0, 1.0]\). The final sample value is just \(S_a + S_n\).
The initial case is where the noise level is set to zero, which should be equivalent to processing the original file. The noise level increments by one each iteration which adds slightly more noise. At each iteration I can compare the output of both jt9 and express8 to make sure they are identical. When so much noise is added that no decodes are produced, the test is stopped and moves to the next file. Getting this right took a while because I need to use the same noise between test runs. To solve this I just generated five different files of the appropriate size from /dev/urandom. I read from those in the test so the noise is identical on each test run. I also switched to using the Decimal type from Python's float to ensure I was not running into some corner case with flaoting point numbers. In the process of this I realized I could produce different results by just using a different noise spectrum against the same file.
When I performed this test originally against the file 2344.flac in my dataset I wound up with output like this
| noise level | noise percentage | JT9 decode count | express8 decode count |
|---|---|---|---|
| 0 | 0% | 14 | 13 |
| 1 | 13% | 16 | 16 |
| 2 | 24.4% | 13 | 13 |
| 3 | 34.2% | 8 | 8 |
The first two iterations of each pass run the original WAV file, then the WAV file with a noise level of zero added. The first pass that injects noise somehow results in more output being decoded by both jt9 and express8. This is not a result I expect because adding noise should not result in more decoded messages, but less messages. To verify that noise is being added in the test case WAV files I created a spectogram of each one with successively higher levels of noise
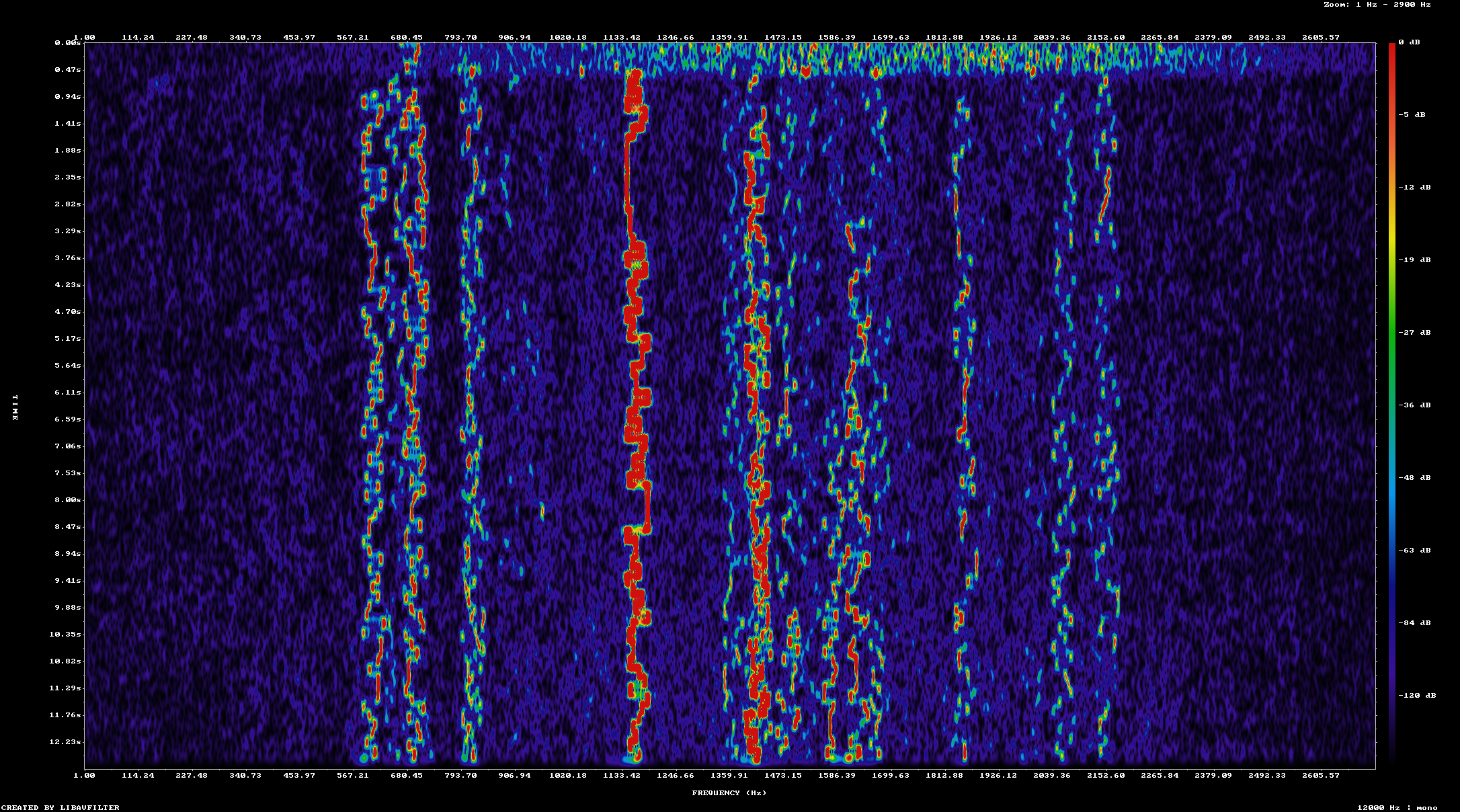
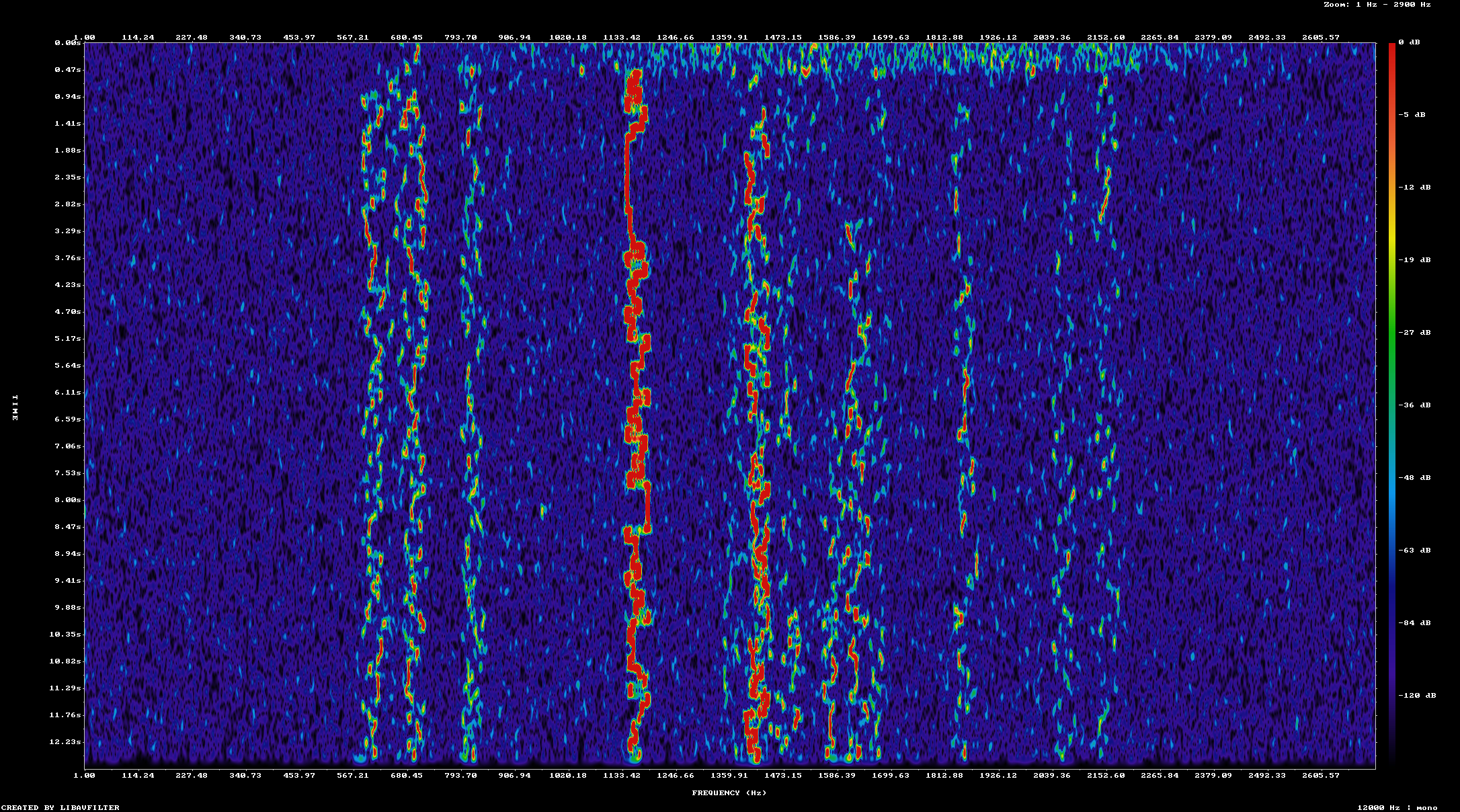
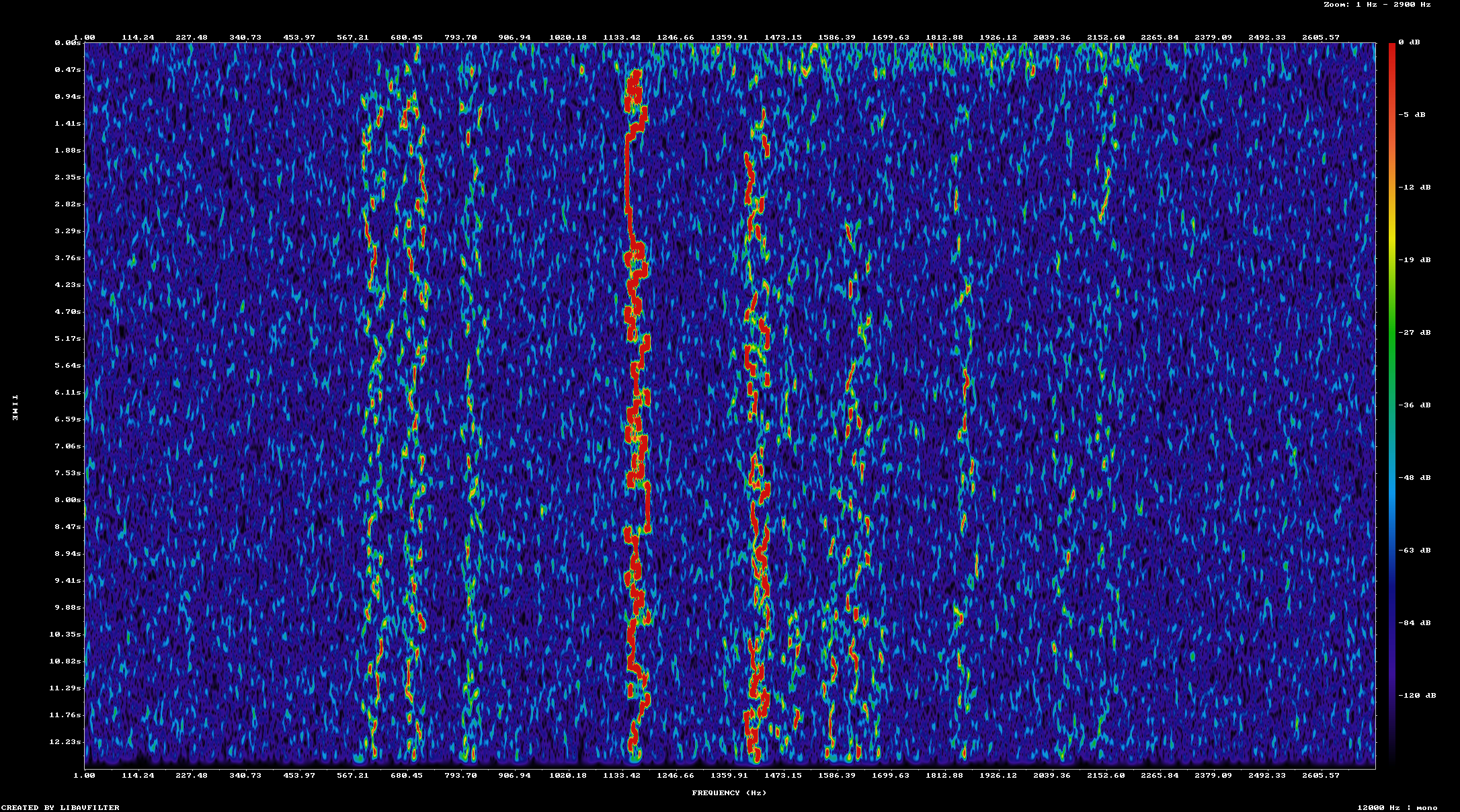
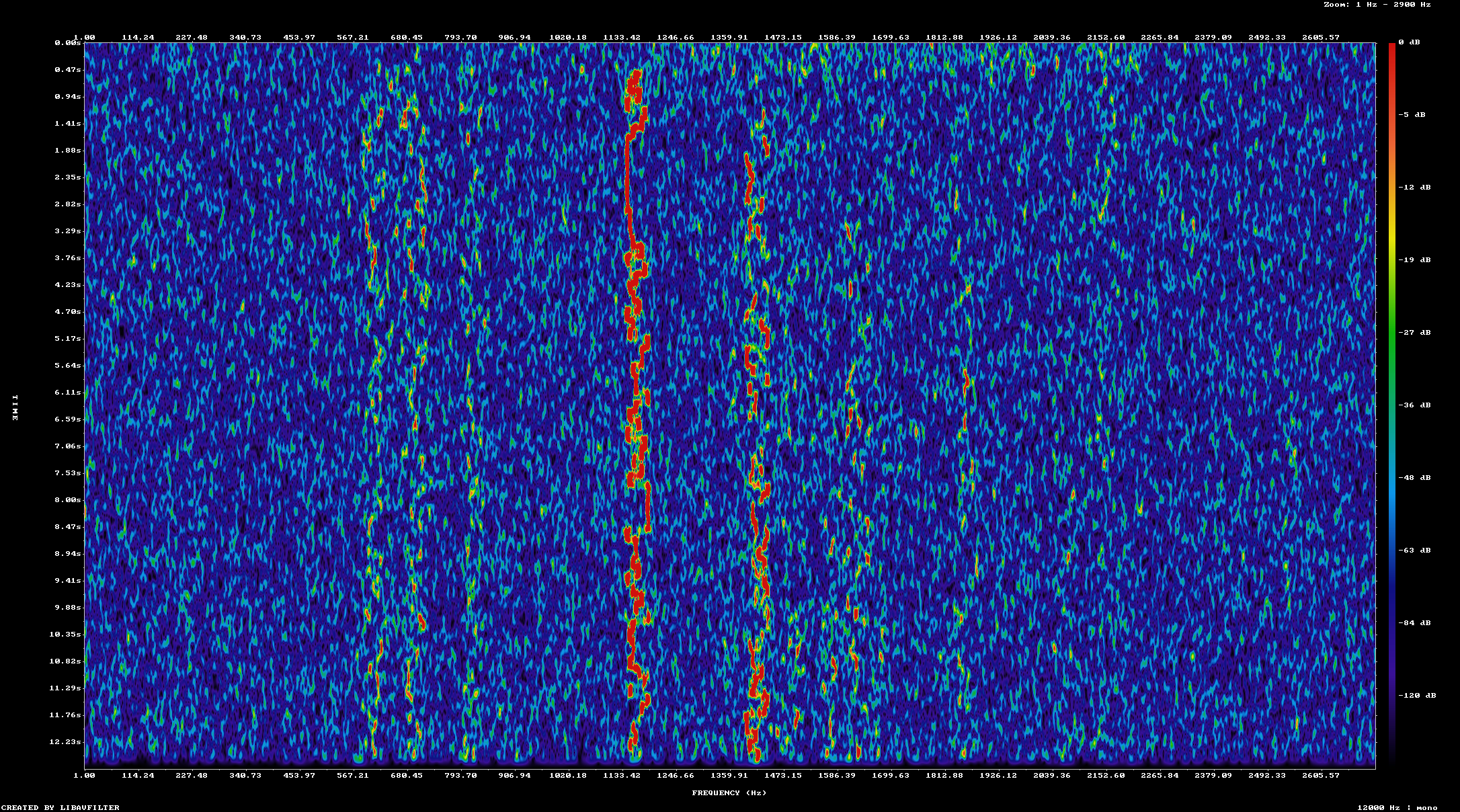
This looks like what I would expect with each test file have a slighty higher noise floor than the prior one. Next I looked at the specific messages that are decoded from each input file. Since this behavior shows up in both jt9 and express8 I decided to compare only the output of jt9 when processing the original file and the file with added noise
| freq. offset (Hz) | message (original audio) | message (noise level 1) |
|---|---|---|
| 588 | no decode | W4IQ KK3KK DM14 |
| 638 | no decode | K7CAR NJ1V DM43 |
| 677 | no decode | KD2YQS KG4OJT -10 |
| 796 | CT2HEX KG7IXX DM43 | CT2HEX KG7IXX DM43 |
| 798 | CT2HEX W9ERR R-05 | CT2HEX W9ERR R-05 |
| 1143 | CQ KG7KDJ DM42 | CQ KG7KDJ DM42 |
| 1349 | <...> VE4ANE EN19 | <...> VE4ANE EN19 |
| 1395 | PY2ANY WS4ASE FM08 | PY2ANY WS4ASE FM08 |
| 1403 | CQ KQ6RN DM13 | CQ KQ6RN DM13 |
| 1460 | KP4WSC KI7RXF CN85 | KP4WSC KI7RXF CN85 |
| 1558 | N3QXC VE3APT FN03 | N3QXC VE3APT FN03 |
| 1607 | KI5ZIS <...> R+03 | KI5ZIS <...> R+03 |
| 1650 | KK4TCE KE0N -11 | KK4TCE KE0N -11 |
| 1836 | CQ KQ4EKW EL95 | CQ KQ4EKW EL95 |
| 2041 | no decode | KD2YQS KD8IAK -02 |
| 2133 | LU6XQB N3BEN CM98 | LU6XQB N3BEN CM98 |
| 2217 | CQ WB5GM EM10 | no decode |
When jt9 processed the file with white noise added it produced four additional decodes. One of the original decodes disappeared. That particular signal was originally received at a SNR of -23 and is from a transmitter very near to me. Due to the pecuilar nature of HF transmission, signals from nearby transmitters are often very weak. The actual process of adding white noise is commonly known as dithering. This is a technique with real world applications. While I intend to revisit this at some point, my conclusion for now is that dithering actually helps the FT8 decoder in some cases. For the moment I am only interested in having my decoder achieve parity with the original FT8 decoder.
Initially I got wildly different output when noise was injected into the file with express8 falling well behind jt9 in decoding performance. This prompted to go back and do more work to understand "AP decoding". Eventually this test produced generally identical results like this when processing the file 2344.flac in my testdataset
| noise level | noise percentage | JT9 decode count | express8 decode count |
|---|---|---|---|
| 0 | 0% | 16 | 16 |
| 1 | 13.0% | 14 | 14 |
| 2 | 24.4% | 11 | 11 |
| 3 | 34.2% | 8 | 8 |
| 4 | 42.8% | 7 | 7 |
| 5 | 50.3% | 5 | 5 |
| 6 | 56.8% | 4 | 4 |
| 7 | 62.4% | 1 | 1 |
| 8 | 67.3% | 1 | 1 |
| 9 | 71.6% | 1 | 1 |
| 10 | 75.3% | 1 | 1 |
| 11 | 78.5% | 1 | 1 |
| 12 | 81.3% | 0 | 0 |
In this case both jt9 and express8 are able to decode 16 messages initially. As more noise is injected, the number of messages decoded drops and eventually reached zero when the audio is 81.3% noise. But the two decoders perform identically. There are some files where this is not true, like when processing the file 1789.flac
| noise level | noise percentage | JT9 decode count | express8 decode count |
|---|---|---|---|
| 0 | 0% | 16 | 16 |
| 1 | 13.0% | 15 | 14 |
| 2 | 24.4% | 12 | 12 |
| 3 | 34.2% | 11 | 11 |
After the first round of noise injection jt9 is able to decode 15 messages from this particular file where express8 is able to only decode 14 messages. This is a minor difference. I compared the output of the decoded messages of both programs when noise is added
| Freq. Offset (Hz) | jt9 SNR | jt9 message | express8 SNR | express8 message |
|---|---|---|---|---|
| 383 | -8.0 | HP1RY N0DL 73 | -8.0 | HP1RY N0DL 73 |
| 855 | -12.0 | CQ KI4TAS EM75 | -12.0 | CQ KI4TAS EM75 |
| 951 | -1.0 | OE9HGV XE1YD -19 | -1.0 | OE9HGV XE1YD -19 |
| 986 | -2.0 | WA2ASQ K4VHE EM64 | -2.0 | WA2ASQ K4VHE EM64 |
| 1272 | -9.0 | KJ5DKL W6YW DM03 | -9.0 | KJ5DKL W6YW DM03 |
| 1413 | 2.0 | WA2ASQ KF9UG EN71 | 2.0 | WA2ASQ KF9UG EN71 |
| 1415 | -9.0 | WD0BRP AC2SB FN03 | ||
| 1555 | -4.0 | EA8BIA W4VBK EL98 | -4.0 | EA8BIA W4VBK EL98 |
| 1680 | -10.0 | SP6AXW WB1V -01 | -10.0 | SP6AXW WB1V -01 |
| 1729 | -4.0 | WD0BRP N9IPO FM14 | -4.0 | WD0BRP N9IPO FM14 |
| 1875 | -8.0 | G3SQU K3ZK -24 | -8.0 | G3SQU K3ZK -24 |
| 1959 | -13.0 | KE0WVJ VE6HQ R-18 | -13.0 | KE0WVJ VE6HQ R-18 |
| 2145 | 0.0 | 4X5JK N0VXY EN41 | 0.0 | 4X5JK N0VXY EN41 |
| 2316 | -9.0 | VE3GLN KC3VJS -12 | -9.0 | VE3GLN KC3VJS -12 |
| 2408 | -10.0 | 9V1YC WW0E EN41 | -10.0 | 9V1YC WW0E EN41 |
The only differences is jt9 managed to decode a message at 1415 Hz. with a value of WD0BRP AC2SB FN03. Keep in mind, this is decoded with added noise. I looked at the output of jt9 on the prior iteration which has no added noise
| Freq. Offset (Hz) | SNR | message |
|---|---|---|
| 311 | -17.0 | K8BL KD5BVX R-09 |
| 383 | -3.0 | HP1RY N0DL 73 |
| 855 | -7.0 | CQ KI4TAS EM75 |
| 951 | 3.0 | OE9HGV XE1YD -19 |
| 986 | 3.0 | WA2ASQ K4VHE EM64 |
| 1215 | -18.0 | CQ N3AZ EL09 |
| 1272 | -6.0 | KJ5DKL W6YW DM03 |
| 1413 | 5.0 | WA2ASQ KF9UG EN71 |
| 1504 | -19.0 | CQ WA3MH FM18 |
| 1555 | -2.0 | EA8BIA W4VBK EL98 |
| 1680 | -8.0 | SP6AXW WB1V -01 |
| 1729 | -2.0 | WD0BRP N9IPO FM14 |
| 1875 | -6.0 | G3SQU K3ZK -24 |
| 1959 | -11.0 | KE0WVJ VE6HQ R-18 |
| 2145 | 3.0 | 4X5JK N0VXY EN41 |
| 2316 | -6.0 | VE3GLN KC3VJS -12 |
In this decode of the original audio file, the message WD0BRP AC2SB FN03 is not decoded at all. Adding noise caused it to be decoded. So what this is further evidence that dithering may enhance the performance of the FT8 decoder. This does leave the question of why express8 does not produce this same output. At this point I've been throughout the code base numerous times and developed a loose understanding of how the decoder works. I also feel like I've established two facts
- the FT8 decoder is very sensitive to initial conditions because dithering the audio file can produce different outputs
- the FT8 decoder as provided in
jt9is dependent on uninitialized memory locations
My general theory is that since jt9 relies on unitialized memory it actually "self dithers" to an extent because values on the stack and heap may be random segments of memory leftover from other computation. I knew that decoding is dependent on establishing synchronization with the start of the transmission. This seems to happen in a subroutine named sync8 defined in ft8/sync8.f90. There is an parameter known as syncmin which if the name is to be believed is some kind of threshold for establishing synchronization. The original WSJT-X code specifies this as either 1.3, 1.6 or 2.0. When express8 invokes the decoder this always gets set to 1.3 from what I can see. The only comparsions against this value are sections of code like this
if( (red(n).ge.syncmin) .and. (.not.isnan(red(n))) ) then k=k+1 candidate0(1,k)=n*df candidate0(2,k)=(jpeak(n)-0.5)*tstep candidate0(3,k)=red(n) endif
All of the comparisons use Fortran's .ge. operator which is just "greater than". So my theory was that lowering this value lowered some initial conditions needed to consider synchronization as established. I temporarily changed the express8 program to use a syncmin value of 1.0 and reran my test against the same file with the same white noise added.
| Freq. Offset (Hz) | express8 SNR | express8 message | jt9 SNR | jt9 message |
|---|---|---|---|---|
| 382 | -8.0 | HP1RY N0DL 73 | -8.0 | HP1RY N0DL 73 |
| 855 | -12.0 | CQ KI4TAS EM75 | -12.0 | CQ KI4TAS EM75 |
| 951 | -1.0 | OE9HGV XE1YD -19 | -1.0 | OE9HGV XE1YD -19 |
| 985 | -2.0 | WA2ASQ K4VHE EM64 | -2.0 | WA2ASQ K4VHE EM64 |
| 1272 | -9.0 | KJ5DKL W6YW DM03 | -9.0 | KJ5DKL W6YW DM03 |
| 1395 | -9.0 | 9V1YC WB9WIU EN70 | ||
| 1413 | 2.0 | WA2ASQ KF9UG EN71 | 2.0 | WA2ASQ KF9UG EN71 |
| 1415 | -9.0 | WD0BRP AC2SB FN03 | -9.0 | WD0BRP AC2SB FN03 |
| 1554 | -4.0 | EA8BIA W4VBK EL98 | -4.0 | EA8BIA W4VBK EL98 |
| 1679 | -10.0 | SP6AXW WB1V -01 | -10.0 | SP6AXW WB1V -01 |
| 1728 | -4.0 | WD0BRP N9IPO FM14 | -4.0 | WD0BRP N9IPO FM14 |
| 1874 | -8.0 | G3SQU K3ZK -24 | -8.0 | G3SQU K3ZK -24 |
| 1959 | -13.0 | KE0WVJ VE6HQ R-18 | -13.0 | KE0WVJ VE6HQ R-18 |
| 2144 | 0.0 | 4X5JK N0VXY EN41 | 0.0 | 4X5JK N0VXY EN41 |
| 2316 | -9.0 | VE3GLN KC3VJS -12 | -9.0 | VE3GLN KC3VJS -12 |
| 2407 | -10.0 | 9V1YC WW0E EN41 | -10.0 | 9V1YC WW0E EN41 |
As a result of this experiment express8 was able to decode the message WD0BRP AC2SB FN03. But it also decoded more messages than jt9 did. This is a good enough explanation of such minimal differences as this one case for now. I can make syncmin a value the user can specify when invoking express8.
This test was actually quite useful as it helped me identify some of the unusual behavior in the dceoder.
Decoding "depth" in WSJT-X
At some point in the midst of this project I realized that jt9 by default runs with a decoding depth of 1. The possible options are 1, 2, or 3. Higher numbers imply more computationally complex analsysis of the audio to decode messages. When I originally started this project I had just located the associated subroutine in Fortran that appeared to decode it and invoked it from my C wrapper. This seemed to work, so I stuck with it. When I figured out the decoding depth option I gave express8 the same option. It did not really produce any difference however. In some cases there was no actual output at all. It was at this point I tracked down and found this segement
! originally from jt9.f90 if(mode.eq.8) then ! "Early" decoding pass, FT8 only, when jt9 reads data from disk nearly=41 shared_data%params%nzhsym=nearly id2a(1:nearly*3456)=shared_data%id2(1:nearly*3456) id2a(nearly*3456+1:)=0 call multimode_decoder(shared_data%ss,id2a, & shared_data%params,nfsample) nearly=47 shared_data%params%nzhsym=nearly id2a(1:nearly*3456)=shared_data%id2(1:nearly*3456) id2a(nearly*3456+1:)=0 call multimode_decoder(shared_data%ss,id2a, & shared_data%params,nfsample) id2a(nearly*3456+1:50*3456)=shared_data%id2(nearly*3456+1:50*3456) id2a(50*3456+1:)=0 shared_data%params%nzhsym=50 call multimode_decoder(shared_data%ss,id2a, & shared_data%params,nfsample) cycle endif
What this actually does it calls the subroutine multimode_decoder which invokes the decoder subroutine for FT8. This happens 3 times. Each time, slightly different amounts of data are passed to the decoder. At least the behavior of invoking the decoder 3 times is apparently critical when specifying higher decoding depths. I refactored express8 to do something approximately equivalent to this and at that point I got more output when I used a depth of 3.
Performance comparison
The performance of the decoder is already adequate on any modern computer if you are monitoring a single frequency. As part of my refactoring however I can decode files in parallel in a single process. There isn't much of an explicit use case for this at present but I did want to see how the performance compared to the original jt9 program. I had all the WAV files prepared in /dev/shm to try and eliminate disk read throughput as a bottleneck. My test data set wound up being 19361 files
Single threaded comparison
To compare the performance of jt9 and express8 I ran each program with instructions to process all the files in a single invocation. Originally I thought I would run this against all 19361 files but that turns out would take an extremely long time. I just picked 200 files to process. I ran jt9 -d 3 --ft8 & express8 decode ft8 --depth 3 --apriori which should be nearly identical.
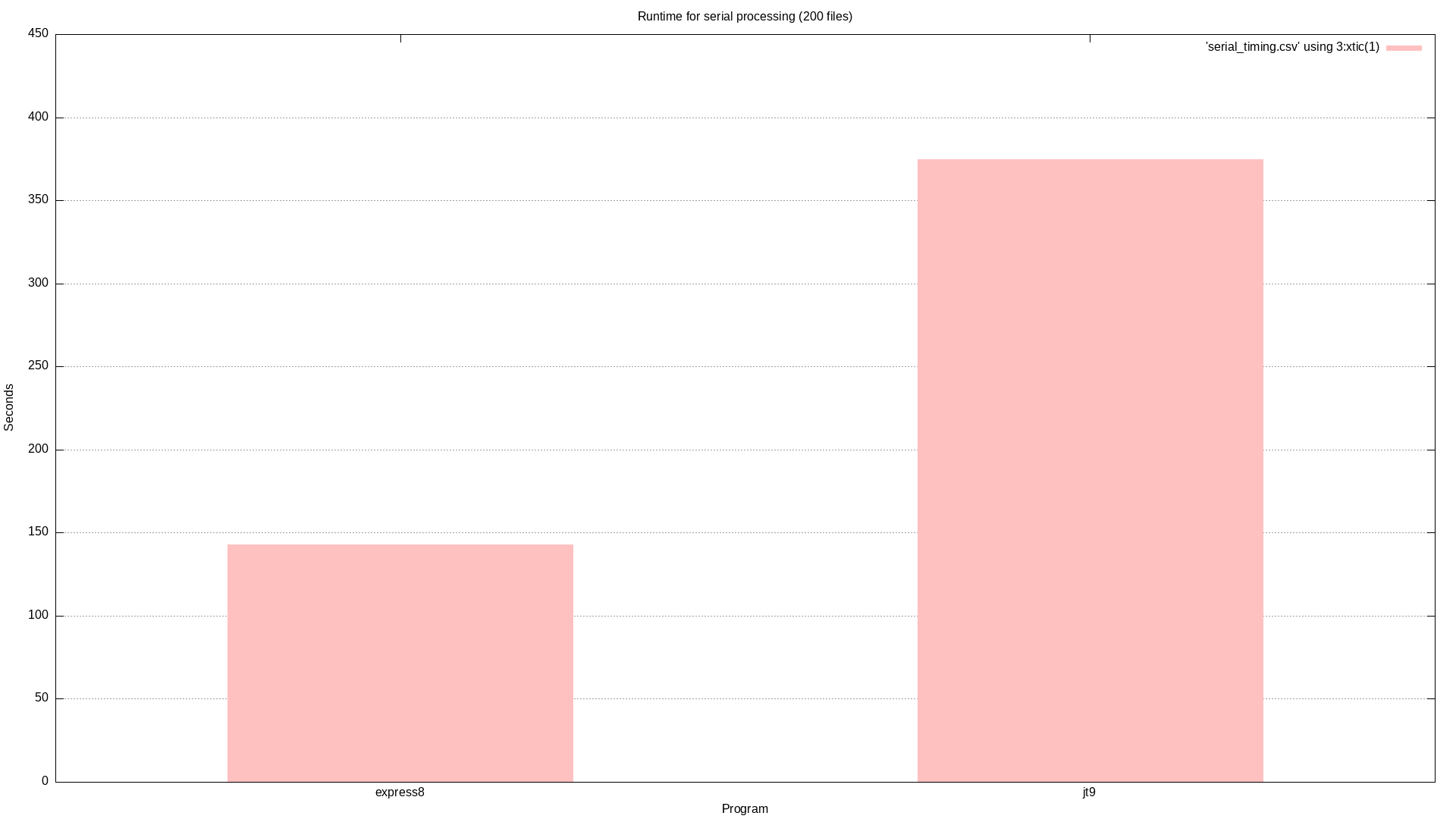
For whatever reason, the runtime of express8 appears to be less than half that of the jt9. I spent quite a while trying to refute this result by finding some flaw in my test. I never could. I didn't make any attempt to actually improve the performance of anything while I was working on express8. My theory is that less time is spent creating FFTW3 plans in express8 since it only creates a very limited number of them.
Multi-threaded comparison
I ran this on a dual socket workstation with dual Intel Xeon CPU E5-2697 v4. This is quite a dated CPU, but each one has 36 hardware threads. I ran the test with a total of 71 threads. Since jt9 has no built-in parallelism what I did was used the GNU parallel command line tool to run multiple instances concurrently. I ran cat allfiles.txt | time -o jt9_parallel.timing parallel -j 71 --max-args 272 jt9 -d 3 --ft8. To get timing data about express8 I ran /usr/bin/time -o express8_parallel.timing --append express8 decode ft8 --apriori --threads 71 --depth 3 --listing-file allfiles.txt
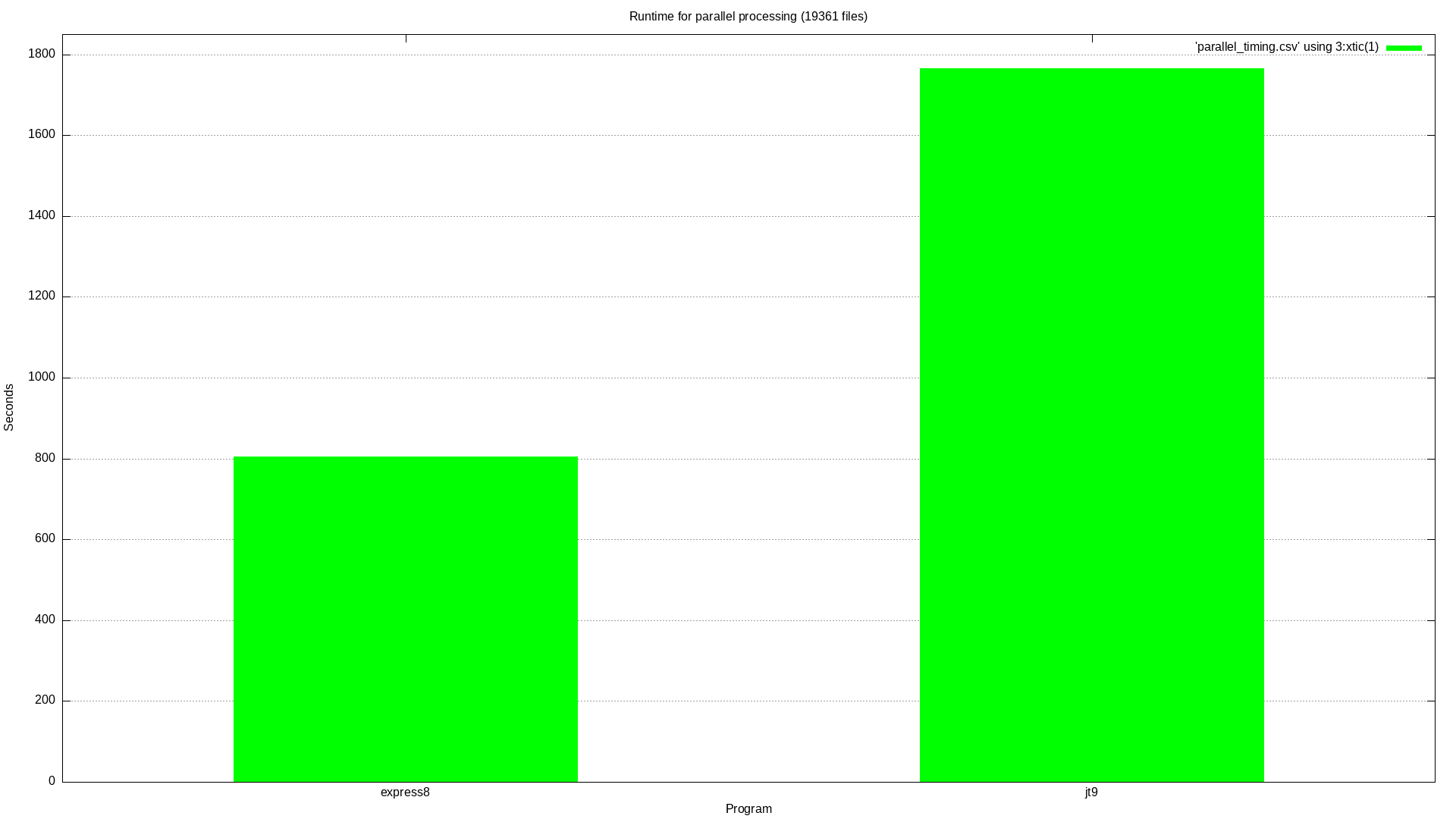
This result is basically identical to the single threaded results.
Conclusion
Overall I think this project has been successful. I've managed to extract out the critical FT8 decoding functionality and refactor into a threadsafe library. I also got to use and learn more about the various tools that come with the Valgrind package. I learned a bunch about Fotran 90 syntax but I doubt that is going to be useful in any other projects.
Source code
You can find the latest source code for express8 on codeberg.